
The first time I watched a demo of GPT-4 having a natural voice conversation, I had the same thought most engineers have: “How hard could it be to build this?”
Turns out, pretty damn hard.
Because what looks like a simple voice interface is actually a complex orchestration of multiple systems working in concert, each with its own scaling challenges, latency requirements, and failure modes. And unlike traditional chatbots where you can get away with some jank in the UX, conversational AI demands near-perfect execution.
A 500ms delay? Users will notice. An out-of-context response? The conversation breaks down. Dropped audio packets? You might as well start over.
I’m not talking about Siri-level “set a timer” commands here. I’m talking about AI that can pull from massive knowledge bases, reason through multi-step problems, maintain context across a 20-minute conversation, and respond with the kind of thoughtfulness that makes you forget you’re talking to a machine. Ask it to help plan your day, and it’ll reason through your calendar, check the weather, factor in traffic patterns, and suggest optimizations you hadn’t considered. Stuck on an architecture decision? It’ll walk through trade-offs across 10 different approaches without you having to prompt it further.
This is the promise of conversational AI, and it’s not some sci-fi fantasy — it’s production reality at companies shipping these systems today. But getting from “cool demo” to “production-ready” requires understanding the full stack, from audio codecs to dialog state machines to infrastructure that can actually scale.
Let me walk you through what’s really involved.
The Fundamental Misconception
Here’s the thing most people get wrong about conversational AI: they think it’s a single model that magically does everything. It’s not. It’s an entire pipeline of specialized components, each solving a specific problem in the audio-to-response-to-audio journey.
Think of it like a modern web application. You don’t just have “the app” — you have load balancers, API gateways, application servers, databases, caches, CDNs, and probably a dozen microservices. Each layer has a job, and the magic is in how they work together.
Conversational AI is the same. You’ve got speech-to-text models converting audio into text transcripts, language models generating responses, text-to-speech systems speaking the output back, dialog managers tracking conversation state, knowledge bases providing context, and routing layers directing traffic. Miss any of these, and your “conversational AI” becomes a frustrating exercise in talking past each other.
The Conversational AI Pipeline
A conversational AI isn’t a single model, but a pipeline of specialized components working together. Here’s what actually needs to happen for a voice conversation:
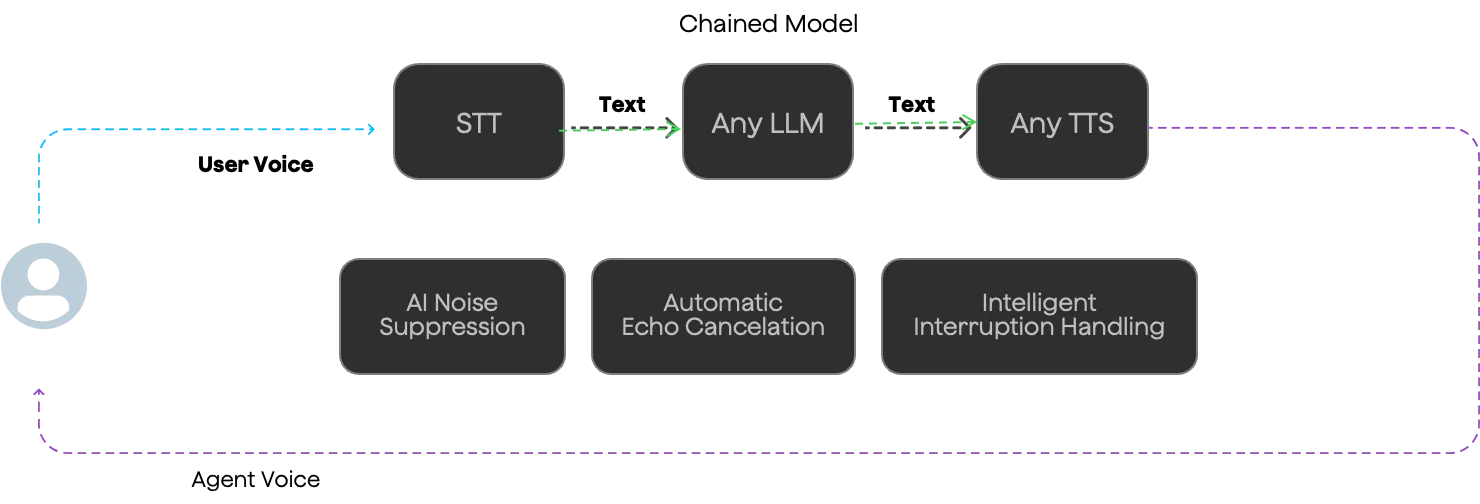
User Audio → Voice Activity Detection (VAD) → Speech-to-Text (ASR/STT) → LLM Processing → Text-to-Speech (TTS) → Audio Response
Let’s break down each component and why it matters.
ASR/STT: Speech-to-Text
What it does: Converts the user’s voice into text that the LLM can process.
The challenge: Real-time accuracy. You need:
- Low latency (< 300ms to feel natural)
- Accurate transcription even with accents, background noise, domain-specific terminology
- Proper handling of silence detection (when has the user actually stopped speaking?)
Voice Activity Detection (VAD) is critical here — it detects when the user starts and stops speaking. Get this wrong and you’ll either cut off users mid-sentence or wait awkwardly for them to continue.
Provider landscape:
- Microsoft Azure Speech: Solid all-around, good language support
- Deepgram: Fast, developer-friendly, good for real-time
- Whisper (OpenAI): Excellent accuracy but higher latency
- ARES (Agora): Optimized for Agora’s infrastructure
Key configuration: Language selection, VAD sensitivity, and whether to use streaming or batch processing.
LLM: The Brain
What it does: Takes the transcribed text, understands intent, generates an appropriate response.
This is where your agent’s intelligence lives. The LLM handles:
- Intent recognition: What does the user actually want?
- Context maintenance: Remembering previous turns in the conversation
- Response generation: Crafting the reply
- Function calling: Triggering actions (API calls, database lookups, etc.)
The flexibility question: Most orchestration platforms let you bring your own LLM via OpenAI-compatible API. This means you can use:
- OpenAI GPT models (GPT-4, GPT-4o)
- Anthropic Claude (better reasoning, safer outputs)
- Custom fine-tuned models for domain-specific use cases
- Open-source models (Llama, Mixtral) if you’re self-hosting
Advanced capabilities you’ll want:
- RAG (Retrieval-Augmented Generation): Connect the LLM to your knowledge base so it can pull in relevant documentation, product info, or customer data
- Function calling: Let the LLM trigger actions like “check_inventory” or “book_appointment”
- System prompts: Configure personality, tone, and behavior guardrails
Latency consideration: LLM processing typically takes 500–2000ms depending on response length and model. This is often your bottleneck.
TTS: Text-to-Speech
What it does: Converts the LLM’s text response into natural-sounding audio.
The quality spectrum:
- Basic TTS (Azure, Google): Functional, consistent, predictable costs
- Premium TTS (ElevenLabs, Cartesia): More natural, expressive, emotional range
- Multimodal LLMs (GPT-4o, Hume AI): Generate audio directly, maintaining prosody and emotion
Key parameters:
- Voice selection: Gender, accent, age, personality
- Speaking rate: Balance between natural pace and information density
- Audio format: Sample rate, encoding (typically 16kHz PCM for real-time)
Latency matters here too: You want to start streaming audio back to the user as soon as the first words are generated, not wait for the complete response. Streaming TTS is crucial for perceived responsiveness.
Avatars: The Visual Layer
What it does: Adds a visual representation that lip-syncs to the generated speech.
This is becoming increasingly important for:
- Customer service kiosks
- Healthcare applications where visual presence matters
- Educational content where facial expressions enhance learning
- Brand experiences where visual identity is key
Technical requirements:
- Real-time lip-sync generation (audio → facial animations)
- Low-latency rendering (can’t add more than 100–200ms)
- Often runs client-side to minimize latency
Agora’s Conversational AI Engine supports avatar integration, as do specialized providers like D-ID and Synthesia.
The Orchestration Challenge
Here’s where it gets hard. You have three (or four with avatars) separate systems that need to work in perfect concert:
The timing problem:
- User stops speaking → VAD detects silence → ASR finalizes transcription → LLM processes → TTS generates → Audio plays
- Every millisecond of latency compounds
- Target: < 1000ms end-to-end for natural conversation
The interruption problem:
- Users interrupt mid-sentence (as they do with humans)
- You need to: Cancel TTS playback, flush audio buffers, start new ASR immediately
- Most homegrown systems struggle with this
The network reliability problem:
- Voice conversations are sensitive to packet loss and jitter, requiring techniques like forward error correction and jitter buffering.
- You need forward error correction, jitter buffering, adaptive bitrate
- Mobile users on flaky networks are your worst case
The scaling problem:
- Each conversation needs persistent connections and stateful processing
- You can’t pool resources like you would with stateless APIs
- One agent instance handles ~6–8 concurrent conversations max
This is why orchestration platforms exist. Building this yourself means solving:
- WebRTC signaling and media transport
- Multi-region edge deployment for low latency
- Agent lifecycle management (spin up, scale, tear down)
- State synchronization across components
- Cost optimization (shutting down idle instances)
What good orchestration provides:
- Sub-second latency pipeline
- Seamless interruption handling
- Network resilience (working even with significant packet loss)
- Automatic scaling based on concurrent conversations
- Unified monitoring and debugging across the entire pipeline
Building Your Own Stack: The Real Decisions
Alright, so you understand the layers. Now you need to decide: build or buy?
The Platform Question
Platforms like Google’s Dialogflow, Amazon Lex, Microsoft Bot Framework, and IBM Watson offer prebuilt components that let you assemble agents quickly. They handle a lot of the infrastructure headaches, provide decent NLU out of the box, and give you admin UIs for non-engineers to manage content.
But they’re opinionated. You’re constrained by their architecture, their pricing model, their rate limits, and their feature set. Want to use a custom embedding model for RAG? Tough luck. Need sub-100ms response times? Hope their servers are feeling fast today. Want to deploy on-premise for security reasons? Most platforms don’t offer that option.
I’ve seen teams waste months trying to bend a platform to their requirements before giving up and building custom. The decision criteria I use:
Use a platform if:
- You’re building an MVP or proof-of-concept
- Your use case maps cleanly to platform capabilities (customer service, simple booking, FAQ bots)
- You have limited engineering resources
- You’re okay with vendor lock-in
Build custom if:
- You need unusual latency or scaling characteristics
- Your domain requires specialized NLU (medical, legal, highly technical)
- You’re building a product where the conversational interface is your core differentiator
- You need full control over data privacy and security
Component Selection for Custom Stacks
If you go custom, you’re picking individual components for each part of the pipeline. If you’re using an orchestration platform, you’ll be selecting from their supported providers for ASR and TTS while bringing your own LLM. Either way, here’s what’s available:
ASR/STT Providers:
- Open-source: Whisper (OpenAI), Vosk
- Paid: Azure Speech, Deepgram, Google Speech-to-Text, AssemblyAI
LLM Options:
- OpenAI: GPT-4, GPT-4o (good all-around, function calling)
- Anthropic: Claude (superior reasoning, longer context windows)
- Open-source: Llama 3, Mixtral (if self-hosting)
- Fine-tuned: Custom models for domain-specific terminology and behavior
TTS Providers:
- Standard: Azure TTS, Google Text-to-Speech
- Premium: ElevenLabs (most natural), Cartesia (low latency), OpenAI TTS
- Emotion-aware: Hume AI (detects and responds to emotional cues)
Voice Agent Orchestration:
For teams specifically building voice agents, there are platforms designed for this use case. ElevenLabs Conversational AI provides full orchestration with their voices built-in, handling the ASR → LLM → TTS pipeline. TEN Framework and Pipecat are open-source frameworks worth watching — they’re designed specifically for real-time voice agents and handle a lot of the streaming complexity for you.
Choosing Your Architecture: Build, Orchestrate, or Bundle?
Before diving into infrastructure, let’s step back and look at the three fundamental approaches to building conversational AI, because this choice will determine everything downstream.
The Fully Custom Stack
When to choose this: You’re building something novel where the conversational interface is your core product differentiator. Maybe you’re doing specialized medical diagnosis, handling highly regulated financial advice, or building gaming NPCs with unique personality systems.
What you get: Complete control over every component, optimal performance tuning, the ability to innovate at the model level, and full data privacy. You can fine-tune every millisecond of latency and customize behavior that off-the-shelf solutions can’t match.
What it costs: Months of engineering effort, deep expertise across ML, distributed systems, and audio engineering, and ongoing maintenance burden. You’re on the hook for reliability, scaling, and every edge case. Budget 6–12 months from start to production-ready.
Example stack: Custom fine-tuned BERT for NLU, Rasa dialog manager, vector DB with Weaviate, custom ASR pipeline, your own TTS trained on brand-specific voice data, Kubernetes deployment on bare metal.
The Orchestration Platform
When to choose this: You need production-grade reliability and performance, but you also need flexibility in your AI models and logic. Your product requires customization that all-in-one solutions don’t offer, but you’d rather not build infrastructure from scratch.
What you get: The infrastructure hard parts are solved (real-time audio transport, scaling, network resilience, interruption handling), but you maintain control over the AI components that matter for your use case. Swap models, integrate custom logic, and differentiate on intelligence while the platform handles the plumbing.
What it costs: Integration time is measured in weeks, not months. You’re paying for platform services, but avoiding the engineering effort of building and maintaining the infrastructure layer. You need API integrations and server-side logic, but not deep infrastructure expertise.
Example approach: Agora Conversational AI Engine as the orchestration layer. You configure it to use your choice of ASR (say, Deepgram for accuracy), your custom fine-tuned LLM or Claude for reasoning, and ElevenLabs for high-quality TTS. You implement custom business logic in your LLM layer — maybe RAG for knowledge retrieval, function calling for API integrations, or specialized prompt engineering for your domain. The platform handles getting audio to users reliably, managing interruptions, and scaling to thousands of concurrent conversations. You focus on the AI behavior, not the infrastructure.
The architecture looks like this: User devices connect to Agora channels → Agora handles audio transport and agent orchestration → Your server handles the LLM calls with custom logic → Agent responds through the same infrastructure. It’s essentially Infrastructure-as-a-Service specifically for conversational AI.
The All-in-One SDK
When to choose this: You’re building an MVP, testing market fit, or your use case maps cleanly to general-purpose conversation. You need something working in days, not months, and you’re okay with the constraints of a fully managed solution.
What you get: Fastest time to market, minimal engineering required, built-in best practices, and no infrastructure to manage. These solutions have battle-tested the entire pipeline and handle most edge cases out of the box.
What it costs: Limited customization, vendor lock-in, potentially higher per-conversation costs at scale, and you’re constrained to their model choices and capabilities. If your needs diverge from their supported features, you’ll hit walls quickly.
Example approach: OpenAI Realtime API or Hume AI’s EVI. Everything is bundled — models, orchestration, even function calling. You write minimal server-side code to handle function execution and session management. Great for prototypes or applications where the conversation itself isn’t your differentiator.
Making the Choice
Most production systems I’ve seen follow a migration path: start with all-in-one to validate the concept, move to orchestration once you understand your requirements and need more control, and only go fully custom if you’re building something truly novel or have specific constraints (data residency, regulatory requirements, unique performance needs) that platforms can’t meet.
The mistake I see most often is starting with a fully custom build when an orchestration platform would have gotten you to market 6 months faster. The second most common mistake is staying on an all-in-one solution too long and trying to hack around its limitations instead of graduating to an orchestration platform when your needs outgrow it.
Infrastructure: Where Theory Meets Reality
This is where I see most teams stumble. The demo works great. The architecture looks clean. Then you try to deploy it and everything falls apart.
The good news: if you’re using an orchestration platform like Agora’s Conversational AI Engine, many of these challenges are abstracted away — they handle agent scaling, network resilience, and audio transport for you. But even then, you need to understand the underlying constraints to make good architectural decisions.
And if you’re building custom? Buckle up. These problems are real and they’re hard.
The Scaling Problem
Here’s the fundamental challenge: conversational AI agents are not stateless. Unlike a REST API where each request is independent, a conversational AI process runs for the entire conversation. That means the compute resources are tied up for minutes or even hours.
Let me make this concrete. Say you deploy an all-in-one model like OpenAI’s Realtime API that takes an audio stream directly. You spin up an agent interface on a 4-core CPU with 8GB RAM. Depending on workload and architecture, an instance may support several concurrent conversations, but scaling typically requires multiple instances.
That’s it. Six conversations per instance.
Compare this to a traditional API server that might handle 1000+ requests per second because each request completes in milliseconds. The resource utilization model is completely different.
This means you need to scale almost 1:1 with your concurrent users. 100 simultaneous conversations? You need roughly 17 instances. 1000 conversations? You need 167 instances. The math is unforgiving.
Multi-Agent Deployment Architecture
Once you accept that you need multiple agent instances, you need infrastructure to manage them. This means:
Container orchestration (Kubernetes is the standard) to automatically spin up and tear down agent instances based on demand. Your deployment needs autoscaling rules that account for conversation duration, not just request rate.
A routing layer (often called an orchestrator) that directs incoming requests to available agents. This is trickier than typical load balancing because:
- You need session affinity — subsequent messages from the same user must go to the same agent
- You need to track agent availability at the conversation level, not the request level
- You need to handle agent failures mid-conversation and potentially migrate state
Common routing strategies include:
- Round-robin with session pinning: New conversations are assigned to agents in sequence, then pinned to that agent
- Least-loaded routing: Send new conversations to the agent with the fewest active sessions
- Affinity-based routing: Try to send related conversations to the same agent for better caching and context reuse
You’ll likely need a dedicated Redis instance or similar to track session-to-agent mappings and agent health state. Don’t try to be clever with stateless routing — it won’t work once you have hundreds of agents.
The Last-Mile Problem: Streaming Audio
Now for the fun part that nobody talks about in architecture diagrams: actually getting audio to and from users reliably.
REST APIs alone are not ideal for real-time conversational audio due to connection overhead and latency. You’ll add 500ms+ of round-trip time just to establish connections, send headers, and wait for responses. In a voice conversation, that’s an eternity.
WebSockets seem like the obvious choice, but they have their own issues. They work great for server-to-server communication where network paths are stable and predictable. But for last-mile delivery to end users? You’re dealing with:
- Variable mobile network conditions
- Packet loss and jitter
- NAT traversal issues
- Client-side network changes (WiFi to cellular)
This is where real-time communication protocols like WebRTC are typically used. But WebRTC is complex — dealing with ICE candidates, STUN/TURN servers, and codec negotiation is a rabbit hole.
A pragmatic solution is using platforms purpose-built for real-time voice at scale. Agora’s Software-Defined Real-Time Network (SD-RTN®) is specifically optimized for this use case — it’s the same infrastructure powering millions of video calls daily, now adapted for conversational AI. Their network handles:
- Automatic route optimization to minimize latency
- Forward error correction and packet loss concealment to maintain audio quality under poor network conditions
- Adaptive bitrate and jitter buffer management
- Global edge servers that reduce first-mile and last-mile latency
If you’re using their Conversational AI Engine, this network layer is built-in — your agent joins an Agora channel just like a user would in a video call, and the platform handles all the audio transport complexity. The result is sub-second latency even for international users on mobile networks.
Alternatively, Twilio’s Programmable Voice or Daily.co can handle the gnarly details of audio transport if you’re building your own orchestration layer. They give you global edge servers, APIs that are actually usable, and take care of codec negotiation and NAT traversal. Yes, it’s another vendor dependency, but it’s one where the alternative is building substantial in-house expertise in real-time media engineering.
Monitoring and Observability
You need specialized metrics for conversational AI:
- Latency breakdown: Time from user audio stop to agent audio start, broken down by component (STT, processing, TTS)
- Conversation metrics: Average conversation length, turns per conversation, task completion rate
- Dialog state tracking: Where in the conversation flow are users dropping off or requesting human handoff?
- Audio quality: Packet loss, jitter, echo detection
- Cost tracking: Per-conversation cost across all components (extremely important with LLM APIs)
Traditional APM tools won’t cut it. You need custom dashboards that let you drill down into specific conversations, replay what happened, and identify patterns in failures.
And you need alerting that understands conversational context. A single failed conversation is noise. A spike in clarification requests might indicate an NLU regression. A pattern of users requesting humans in a specific conversation branch suggests a dialog policy problem.
The Path Forward
Building production-ready conversational AI isn’t a weekend project, but it’s also not as monolithic as it first appears. The key is choosing the right approach for your specific situation.
If you’re just starting out or validating product-market fit, begin with an all-in-one solution. Get something working in days with OpenAI’s Realtime API or Hume AI. Learn what your users actually need from the conversational interface. These solutions have enough flexibility for exploration without the commitment of infrastructure.
Once you have traction and understand your requirements, consider graduating to an orchestration platform if you need:
- More control over your AI models and their behavior
- Better economics at scale (paying only for the components you use)
- Custom integrations that all-in-one solutions don’t support
- The ability to differentiate on AI capabilities
Agora’s Conversational AI Engine is a strong option here — you maintain control over the components that matter (your LLM, your prompts, your knowledge base) while delegating the hard infrastructure problems (real-time audio, scaling, network resilience, interruption handling) to a platform designed specifically for this use case. You can start with their supported providers for ASR and TTS, then integrate custom LLMs with RAG, function calling, or specialized reasoning as your needs evolve.
Only go fully custom if you’re building something truly novel, have unique regulatory requirements, or need optimizations that platforms can’t provide. This is the path for companies where conversational AI is the product, not a feature. Budget 6–12 months and a team with diverse expertise — ML engineering, distributed systems, audio processing, and DevOps.
Regardless of your approach, the teams that succeed are those who:
Measure relentlessly: Instrument everything, track conversation-level metrics, and use data to drive decisions. Know your latency breakdown, conversation completion rates, and where users are struggling. For orchestration platforms, this often means integrating their callbacks and event streams into your analytics pipeline.
Iterate on dialog design: Treat conversation flow as a first-class design problem, not an afterthought. Your dialog policies, clarification strategies, and error recovery patterns matter as much as your model selection. Test with real users early and often.
Plan for scale thoughtfully: Understand the resource model before you have scaling emergencies. Even with orchestration platforms handling the infrastructure, you need to think about costs per conversation, peak concurrent usage, and how different architectural choices affect your unit economics.
Invest in observability: The ability to replay conversations, drill down into specific failures, and identify patterns in user behavior is crucial. Build logging and monitoring that captures the full context of each conversation, not just API call metrics.
Don’t over-engineer early: Start with simpler approaches and add complexity only when you hit real limitations. Many teams waste months building custom NLU pipelines when fine-tuning prompts on an LLM would have worked fine. Use the simplest stack that meets your requirements, then optimize the bottlenecks you actually encounter.
Conversational AI is moving from cutting-edge research to production infrastructure. The companies that figure out how to deploy these systems reliably, scale them efficiently, and iterate on them quickly will have a massive advantage.
The question isn’t whether conversational interfaces will replace traditional UIs for certain use cases — they will. The question is whether you’ll be ready when your users expect them.
Want to dive deeper into production conversational AI architecture? I’m documenting lessons learned from real-world deployments and would love to hear what challenges you’re facing. Reach out, or subscribe to get future technical deep-dives delivered straight to your inbox.







