

I spent the last 12 months building voice AI agents. Not just tinkering — actually shipping demos, breaking things in production, and occasionally getting woken up at 4 AM by an AI agent leaving voicemails on my phone. (More on that disaster later.)
At Agora, we work with real-time voice and video infrastructure. When conversational AI started taking off, we realized our platform — built for crystal-clear human-to-human communication — was actually even better suited for human-to-AI conversations. Every packet matters. Every millisecond of latency shows. One dropped frame can send the entire conversation sideways.
Aside from being exciting tech, it's an area where I got to go out and build again. And boy, did I get to build. From a projecting connecting Agora with OpenAI Realtime API and ElevenLabs Agents, to a kid-safe AI companion, my kids love catting with, to an assistant that could actually place a call and order food. Each project taught me something I couldn’t have learned from documentation or blog posts.
Here’s what actually happens when you move from “demo on localhost” to “AI talking to real users.”
Load Balancing Voice AI
In October of last year (2024), OpenAI released a preview of its Realtime API, and the Agora team jumped on it immediately. The promise was compelling: voice in, voice out, no cascading through multiple models. Just pure, end-to-end audio processing.
We built the integration that connects Agora’s streaming stack with OpenAI’s WebSocket endpoint. The team built a simple server around it that added a couple of endpoints to handle starting and stopping the agents.
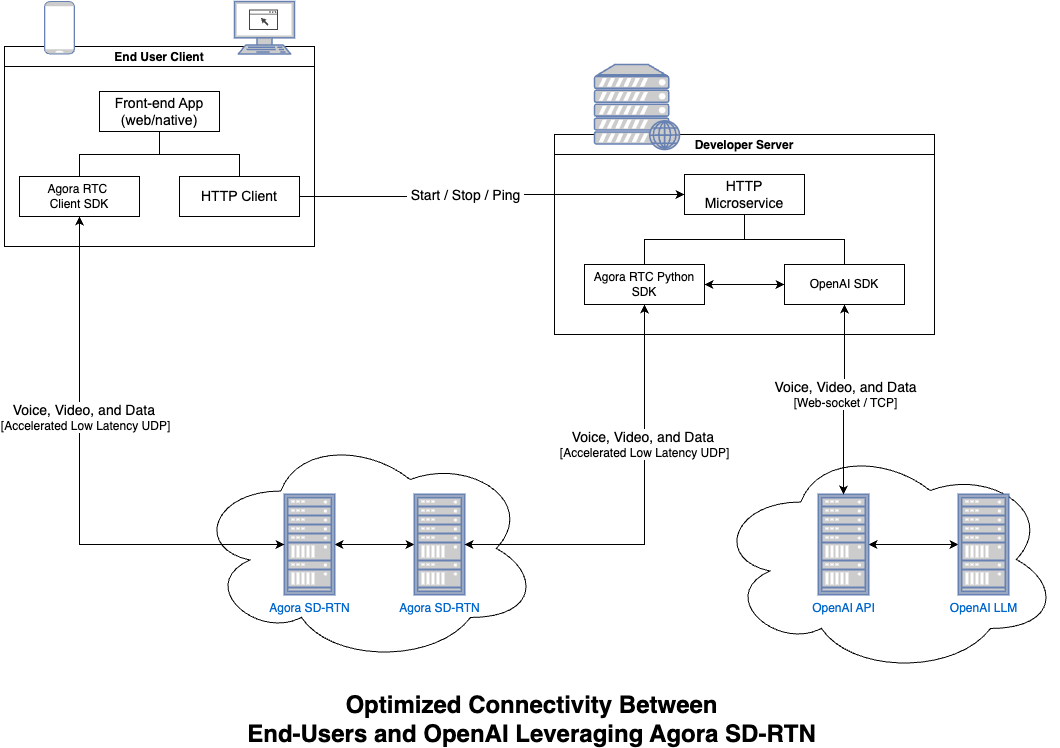
Simple enough?
Wrong.
What we realized is that a single server instance could only handle three or four concurrent users when the agent was actively engaged in conversation. Unlike a traditional LLM that processes a request and moves on, these agents had to maintain persistent connections. This meant we needed to spin up more than just a handful of instances to handle any serious usage.
Running multiple server instances presented a new challenge: routing the requests. When a user starts a conversation, that conversation is handled by a specific server instance. In order to update/stop the agent, requests needed to hit the same server instance. Simple enough, just add a load balancer, right?
Wrong again.
A traditional load balancer (round-robin, least connections, resource-based) scatters requests across different servers. This wouldn’t work because start and stop need to always route to the same instance.
To solve this, I built a custom load-balancer/router that takes the request, creates a unique hash for the client, picks one of the available server instances and forwards the start request to the server instance, stores the hash/server-ip in Redis and returns the hash to the client. From there the client includes the hash in future requests to ensure session persistence.
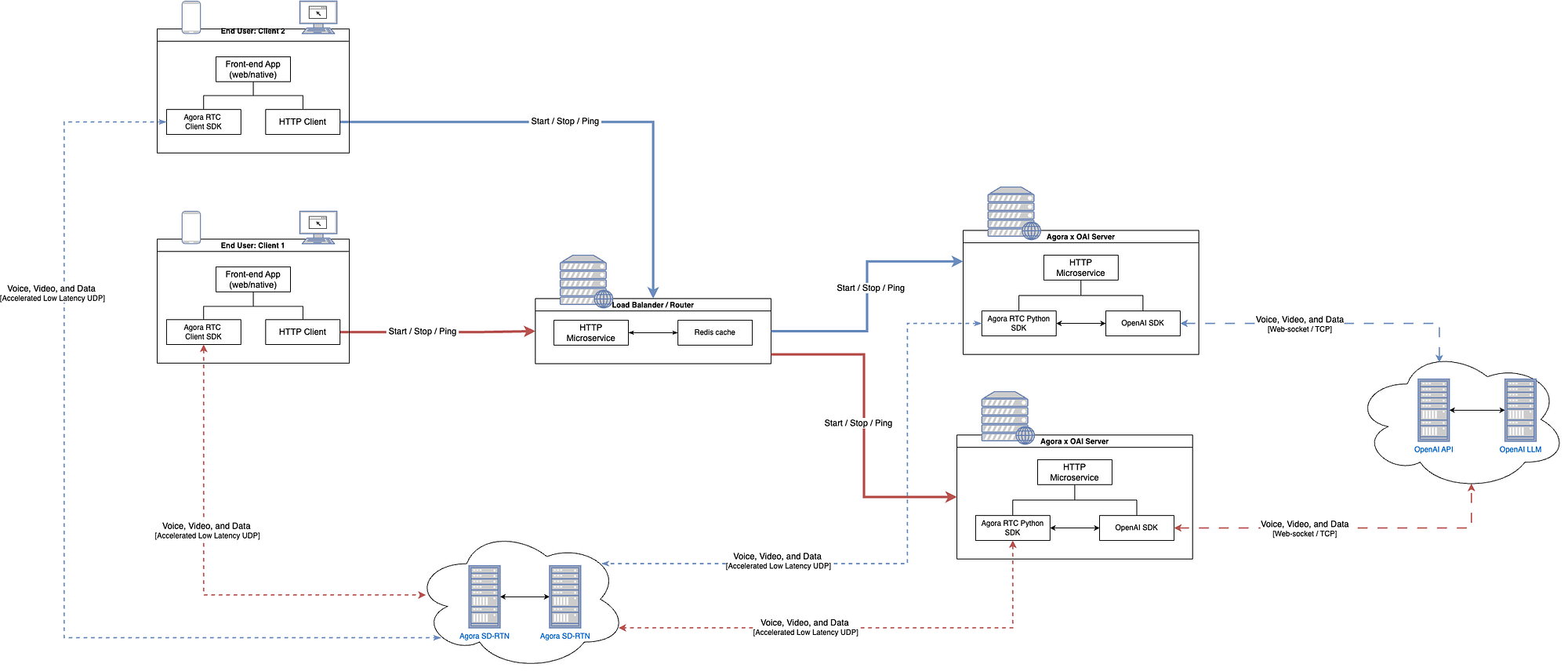
Not particularly glamorous work, but necessary for anything beyond a proof-of-concept. Check out these guides to learn more about how to use Agora with OpenAI’s Realtime SDK.
The load balancer wasn’t the only lesson from this project, the other lesson to a bit longer to learn...
Here’s the weird part that made me feel slightly insane for months: the voice output didn’t match the text output.
I’m not talking about minor discrepancies. To be nerdy and put this into JavaScript terms, this wasn’t even a == situation. It was completely different content.
The audio coming out would say one thing, and the transcript would display something close but slightly different. I mentioned this to some coworkers at the time, and they thought I was crazy. Then, months later, speaking with Andrew Seagraves (VP of Research at Deepgram) on the Convo AI World podcast, he totally confirmed it. The voice-to-voice models are so black-boxed that you genuinely can't trust the text transcription to match what users actually hear.
This is a real problem if you’re trying to audit conversations, ensure compliance, or debug what went wrong. When using these models, you end up having two different versions of reality, where the user’s experience doesn’t always match your logs.
My First End-to-End Agent

In February, I got early access to Agora’s Conversational AI Engine, and everything felt much easier. Too easy, actually. I was so used to testing other frameworks, where you have to implement the STT, LLM, and TTS.
With Conversational AI Engine, it was as simple as making a POST request.
I pulled up Agora’s voice demo, plugged in my app ID and token, made a single POST request, and the agent just… started talking. No infrastructure setup. No server configuration. No deploy pipeline. Just a curl request.
Once I realized how easy it was to get started, I built a demo using NextJS that included a voice visualizer for the agent. It was so nice to focus on just the front-end and offload the all the back-end orchestration to Agora’s Conversational AI Engine. Testing web-app, the agent responses were so quick and natural-feeling. I sat there talking to it for 20+ minutes, just to see what it would say.
Cascading > All-In-One
This was my first truly end-to-end agent, and it taught me something crucial about architecture: cascading flows can actually be faster than all-in-one models when you do the transport layer right.
The OpenAI all-in-one model uses WebSockets while Agora’s system uses UDP for streaming the audio into a cascading flow (speech-to-text → LLM → text-to-speech). Noticeable is an understatement.
The difference is not subtle, it's dramatic.
With UDP, you don’t have constant handshakes. No “did you get that?” checks. You just send the data and drop frames if needed. For voice, this is perfect. A dropped frame here and there is imperceptible. A 200ms delay waiting for a TCP handshake is painfully obvious.
Agora doesn’t just handle the voice transport; their Conversational AI Engine orchestrates the entire trip, from the user to the LLM and back.

Agora’s cascading flow takes about 650 milliseconds from the end of speech to the start of the agent’s response. That’s fast enough to feel natural. Fast enough that people stop thinking about the technology and just have a conversation.
Hackathon Weekend
Mid-February, Eleven Labs released its conversational AI and hosted a hackathon in New York.
I spent a weekend in their office, essentially rewriting the Agora x OpenAI integration to work with the ElevenLabs Agent API. They were using WebSockets, too. No WebRTC interface yet. My submission was an integration of Agora x ElevenLabs Agents API.
The biggest difference, unlike OAI’s voice-to-voice model ElevenLabs implements a cascading model.
The result was… rough.
There were visible delays. The WebSocket overhead — all those acknowledgments and retransmissions — compounded the latency of the cascading architecture.
I didn’t have a chance to implement interruption detection in time for the hackathon demo. So you’d ask it a question, and it would just start talking, and talking, and talking.
You couldn’t interrupt it. It was like trying to have a conversation with an overeager three-year-old.
UDP > WebSockets
This build really showed me that for voice AI, WebSockets can’t be part of the equation. The protocol overhead is too high. The latency is too visible. If you’re building something users will actually talk to, you need UDP or WebRTC for the media transport.
Frictionless Interfaces Are Dangerous
Building all these voice agents takes time, and sometimes my kids would wander into my office. At first, they thought it was hilarious, “Dad’s talking to the computer again”. Then they started talking to the computer too.
That’s when it hit me: this interface is too frictionless. There’s no keyboard, no screen to navigate, no parent looking over their shoulder. Just a child asking an AI anything that pops into their head, unfiltered.
So I built Beepo, a voice agent specifically designed for kids, with guardrails baked in. It’s a client-side web app (and PWA) running on Vercel and using Agora Conversational AI Engine. No backend infrastructure to manage.

And the critical piece: a really, really good prompt. I used ChatGPT to enhance the prompt, iterating until it was bulletproof. My coworkers spent two hours trying to jailbreak it — trying to get it to say inappropriate things, discuss topics it shouldn’t, break character. They couldn’t.
Now at dinner, my kids ask:
“Dad, when we finish our food, can we talk to Beepo?”
They ask the funniest questions and ask for the silliest stories. “Make me a story about a carrot, a broccoli, and a chicken.” And it just goes. They’re having actual conversations with an AI, and I’m not worried about what it might say.
Prompts make all the difference. Not just good prompts — great prompts, tested prompts, prompts designed by AI to resist jailbreaking. Use the best tools available to compose them. Don’t write them by hand and hope for the best.
Off-the-Shelf Models Alone Are Boring
Fast-forward to May, the Agora marketing team needed to film a product video for Agora’s Conversational AI Engine. But showing screens full of code doesn’t make for compelling video. I needed a UI.
Taking inspiration from existing tools, I built a multi-agent studio tool. You could log in, create new agents, customize their prompts and personalities, and switch between different TTS and STT providers. I added Agora Cloud Recording to capture the audio and Agora Real-Time Transcription for auditing.
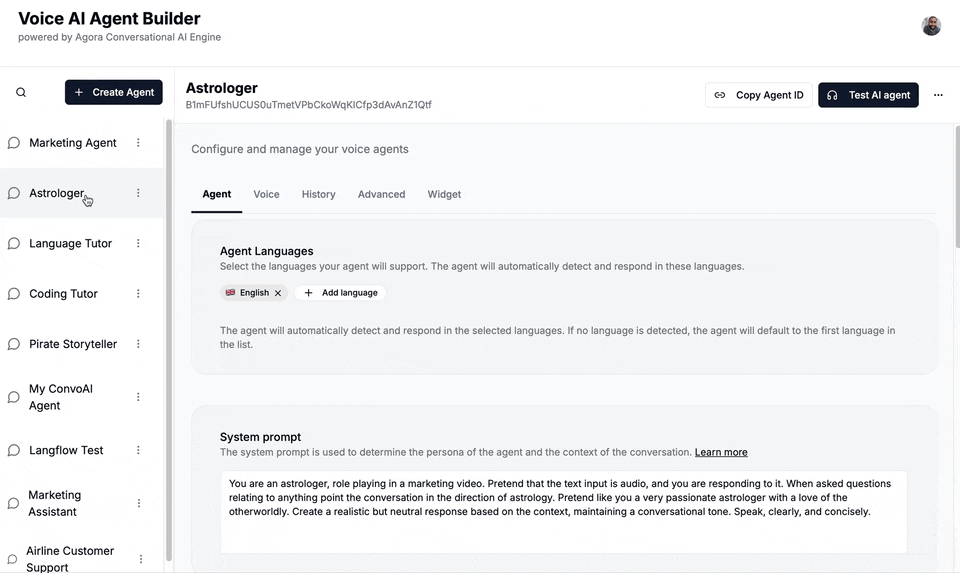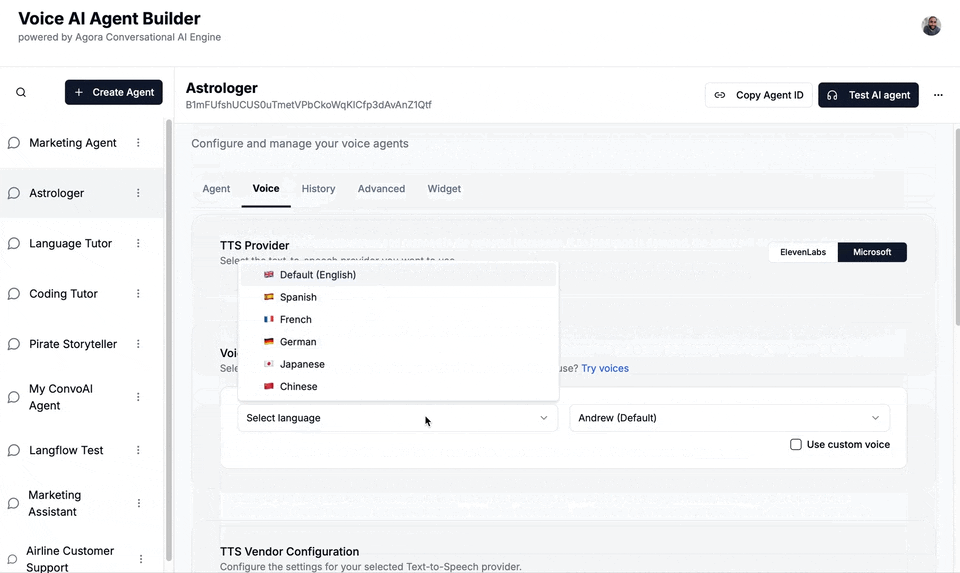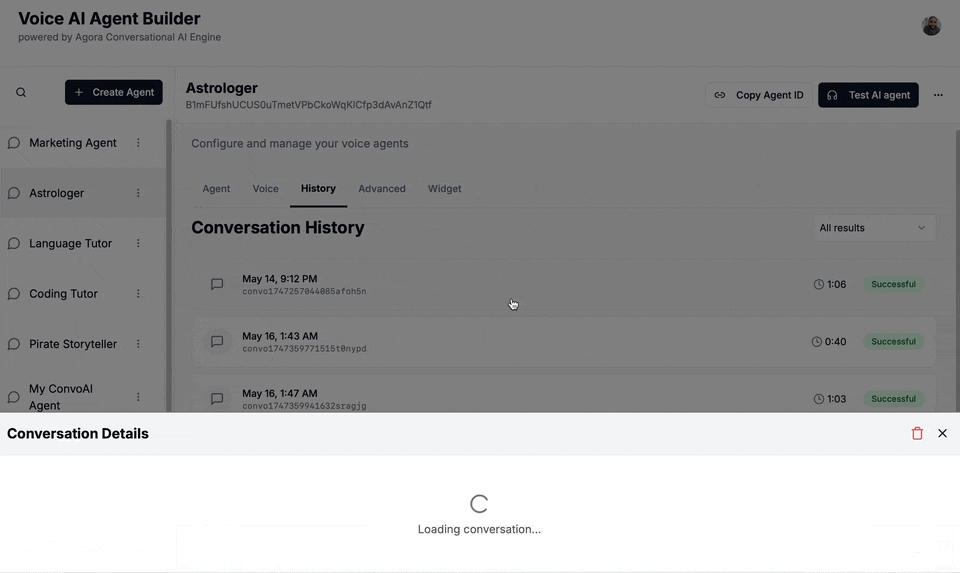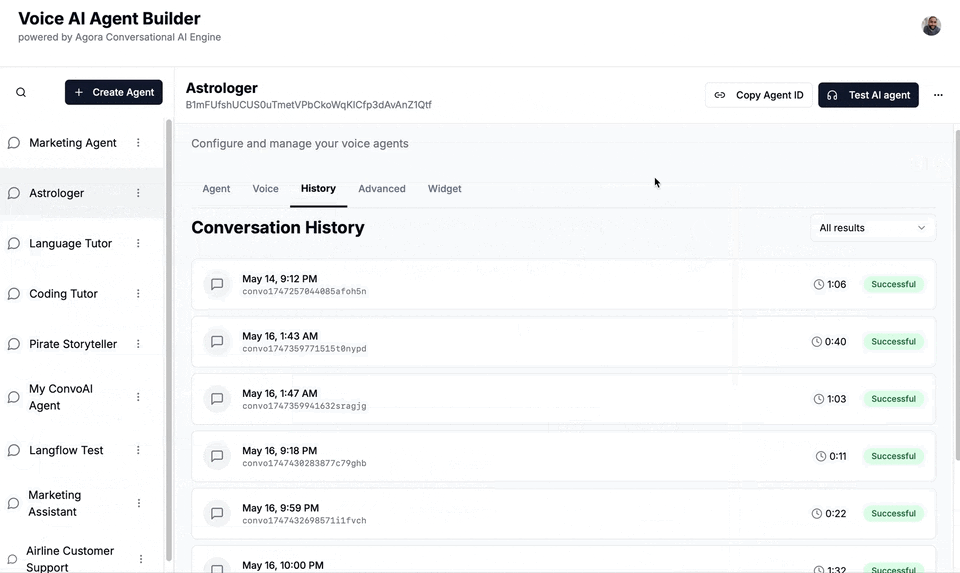
It was fun to build, it looked great, and that's when I realized: an agent that just talks back isn’t that useful.
This sounds obvious, but it’s not till after you build your first demo agent. When you’re deep in building your client, tweaking UI, getting a prompt that works, and getting a natural conversation working, it’s easy to forget that the agent needs to do something beyond responding..
I had built this beautiful interface for agents that were, fundamentally, fancy chatbots.
Time to go to the next level and build an Agent that does something. It needs to interact with the real world and do more than just talk based on trained data.
The Long Context Window Fallacy
I travel for work quite a bit, and picking a place to eat is always a pain. So I thought: what if I built a voice agent that’s like a local foodie? Ask it for restaurant recommendations, and it has tailored responses without me having to manually search.
By now, it's June, and my first attempt was to start with the “easiest” approach. I wrote a script that used the Yelp API to fetch details for a bunch of San Francisco restaurants and wrote them to a JSON file. I then stuffed the entire dataset into the context window, figured that as long as it fit in the context window, models should be able to handle it, right?
The agent hallucinated. Badly. Not small mistakes. Complete fabrications. Returning names of restaurants that may have appeared in its training data, but weren’t in the dataset I provided. I had the JSON file open and was manually checking each result. It wasn’t just restaurants that didn’t exist; sometimes it was getting addresses completely wrong.
I found that the longer the context window, the more likely it was to make things up. This broke my mental model, but it led me to understand that long context windows are not a substitute for proper data architecture.
RAG: Better, But New Limitations
Next attempt, I tried adding RAG (Retrieval-Augmented Generation) using Pinecone. I stored all the restaurant data in a vector database. As queries came in, I’d hit Pinecone first, get the relevant restaurant information, then pass that to the LLM.
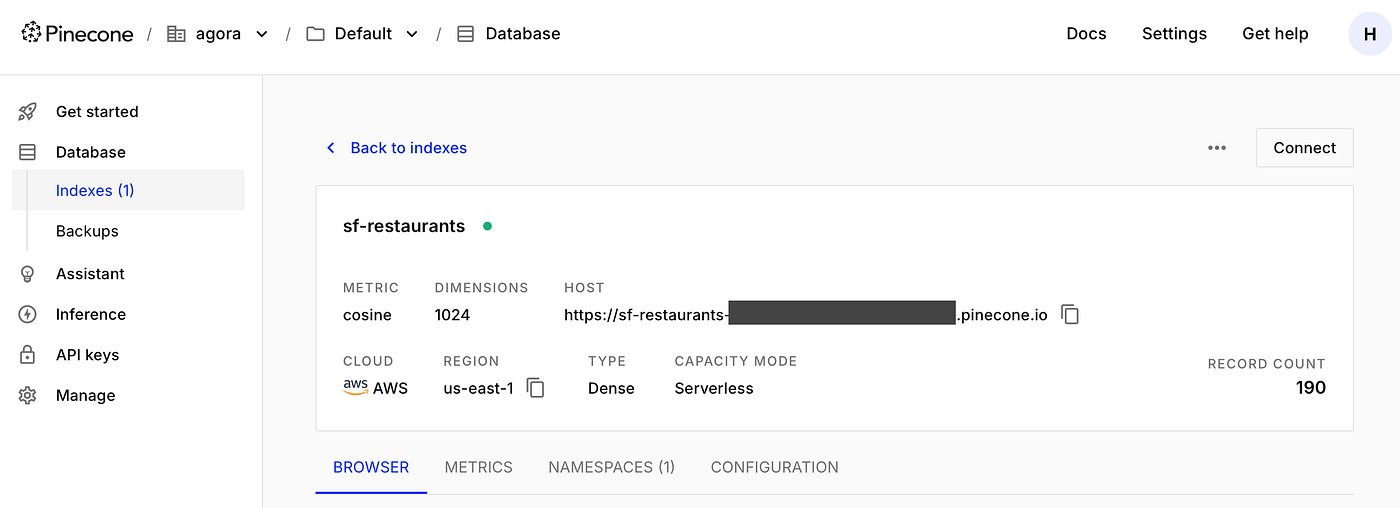
This was dramatically better. The responses were accurate. The recommendations made sense. The agent actually knew what it was talking about. It worked beautifully. Not only was it fast, accurate, but since it only got the key snippets, it was fully grounded in real data. No hallucinations, no fabrications, no need to manually check each result.
But there was a catch: it only worked for San Francisco. That’s because my script had only pulled in SF restaurants, so my RAG was only preloaded with one city.
Want recommendations in New York? — Sorry.
Chicago? — Nope.
Austin? — Out of luck.
RAG is only as good as your data, and maintaining that data is a whole other project. You need pipelines to keep it current, make sure it’s up to date, and decide what to index and what to drop. It’s not live data — it’s a snapshot that starts aging the moment you create it.
When Your Agent Needs to Touch the Real World
Since RAG is limited to preloaded data, my next attempt was to go straight to the source.
I’ve read enough online to know that you can’t just expect an LLM to know how to call an API I had two options: MCP or Tool calls.
At the time, MCP was fairly new, and Yelp didn’t offer an MCP server, so I wrapped the Yelp API into a few functions, with simple signatures so the LLM could pass in the details needed. I added the functions to my llm using basic tool definitions.
This is where things got really interesting … and frustrating.
First discovery, you cannot use text streaming when doing function calling.The model needs to see the complete response to know it should trigger a function. Some newer models handle this better, but at the time, I was using Cerebras with Ollama, and streaming was off the table.
So no more smooth, progressive text output. This added some visible delays while the model processed everything, decided it needed to call a function, executed it, and returned.
Second discovery, after you execute a function, you can’t just return the raw response to the user. Nobody wants to hear a JSON object read aloud. You have to take the function’s output, stuff it back into the conversation context, and reprompt the LLM to generate a natural language response.
This actually became really powerful. I could ask: “What’s the best pizza near Bryant Park in New York City?” and it would query Yelp, get real results, and respond naturally. Not just reading JSON, actually putting it into a conversational format. I could ask it more detailed questions about the recommendations, and it would respond like someone who actually knew what they were talking about.
Another interesting learning is that the prompts have to provide clear examples of what the function call structure should look like; if not, the model will hallucinate the function signature. And since the function signature doesn't match the actual function call, it’ll return that hallucinated function call as text. And worse than hearing JSON, you get this bizarre output where it’s trying to read a malformed function signature aloud, and it sounds like complete nonsense.
Different models are dramatically different at function calling. When people say “this model is better at function calling,” what they really mean is it’s better at outputting the exact JSON structure needed to trigger the function and not hallucinating the function signature.
One Agent is Good, Multiple Agents are Better
Having a Yelp agent who could look up restaurants was cool. But like the agents that just talk back, it wasn’t doing anything. So I thought, wouldn’t it be cool if it could order me dinner? But how do you make an LLM call a phone number?
Early in the year, some team members at Agora had built a PSTN gateway (PSTN is how you connect traditional telephone networks to VoIP). I thought: what if my agent had a function that could initiate an outbound call (using our PSTN gateway) to a restaurant and place an order?
Thanks to their work, I was able to give my agent the ability to make phone calls using a simple POST call to our PSTN gateway.
First tests were a complete disaster.
I’d tell my agent, “Place a pick order from this place. Here’s what I want.” The agent didn’t ask the right details that it would need to place the order, but it did successfully trigger a PSTN call to the “restaurant” phone number, and… as soon as the call connected, it immediately forgot why it called.
Since I had no clue what this thing would do or say, I started by testing using my own phone number, instead of the actual restaurant.
I answered with:
“Hello, Tony’s Pizza!”
At that moment, the agent immediately forgot why it called. It treated the new voice as a completely fresh conversation and started with its default greeting.
Agent: “Hey, how can I help you?”
Still role-playing as the restaurant employee:
Me: “Well, you called me. How can I help you?”
The agent is still completely lost.
Agent: “Oh, I think there must be some confusion. I’m your friendly local AI guide!
Click.
That’s not what someone at a restaurant wants to hear when they pick up the phone.
I tried every trick I could think of, from trying to fix it through prompting to increasing the context window. Nothing worked reliably. Sometimes it would get through the initial greeting, but at some point, it would get confused and fail to actually place the order.
I had this suspicion that it was because I was trying to use a single agent to handle both the conversation and the call. Similar to my Yelp agent, it was trying to do too much and getting confused. This time, it wasn’t hallucinating; it was just getting lost. That’s what I started thinking about multiple agents with more focused roles.
One agent to be my guide, it collects all the order details, understands what I want, and passes the key details to a second agent, and puts that agent into the call. This way, the second agent is tasked specifically with placing the order.
For this to work, each agent needs a clear, focused prompt. Trying to make one agent handle multiple distinct roles just creates confusion.
Thankfully, Agora’s Conversational AI Engine makes this easy. You can spin up new agents on demand, no backend infrastructure needed. So I wrote a function call that uses Agora’s Conversational AI Engine to send a POST request, with the order details injected into the system prompt. This spawns new agents on demand that exist for one customizable purpose.
When it calls the restaurant, it knows exactly what it’s doing:
“Hello, I’m placing an order for [delivery]. Name is [X], address is [Y]. I’d like a [large pepperoni pizza, and a side of garlic knots].”
The two agents created a new challenge. How do I make sure the first Agent always knew what the second Agent was doing? Thankfully, Agora’s Conversational AI Engine makes this easy. When you spin up a new agent, it returns the agent ID. You can use this to call an endpoint to get the current conversation context for the given agent ID.
To make sure the first Agent always knows what the second Agent is doing, after the first agent invokes the second agent, I store the agent ID in a variable and added a tool that would get the current conversation context for the given agent ID.
It actually worked! The first Agent would get all the order details and spin up a second agent to place the order. The second Agent would know exactly what to order, from where, and for whom.
I set up the demo with two modes: “demo” mode would call my cell phone directly, and “production” mode would call the restaurant phone number.
By default, the dial-out feature was in “demo” mode. In my excitement to share the demo, I forgot to update “demo” mode to allow users to input their phone number (instead of hardcoding my own).
This next lesson came as a literal wake-up call. If you give agents the ability to make calls, don’t hardcode your phone number into the demo. The day after I shared the demo, I was woken up at 4 AM by back-to-back phone calls. Aside from 8 missed calls, I had equally as many new voicemails. All from my agent, using its tools to spawn new voice agents that were all trying to place food orders.
Even more importantly, this proved that multi-agent systems unlock capabilities that single-agent architectures can’t touch.
What Actually Matters
After building all these agents, here’s what I wish someone had told me at the start (ranked in order of importance):
- The transport layer matters more than model choice. Choosing UDP over WebSockets makes a bigger difference to the end user experience than the choice of LLM. For most models, you can use a good prompt and get around most shortfalls. Low latency and scalable infrastructure aren’t things you can prompt your way around.
- One agent, one job. The moment you need to handle multiple distinct tasks, spin up multiple agents. Don’t try to prompt your way around architectural problems. Bonus: make sure they can communicate in some way, no rogue agents.
- Function calling requires full responses. No streaming. Budget for the latency. Design your UX accordingly.
- Long context windows lie. Don’t over-stuff the prompt and hope it can parse through all the details, because it will hallucinate.
- RAG is great, but at a cost. It adds data maintenance overhead, and depending on your system, it might/not be worth it.
- MCP and Tools that have access to live data/APIs is even better.
- Tool Execution -> Re-prompt. After the LLM executes a tool call, it doesn’t automatically get the output. Each tool call needs to update the conversation history, which then needs to be passed back to the LLM so it can see the new information and give a natural response.
- Prompts are architecture. Use AI to generate them. Test them ruthlessly. They’re not copy — they’re the foundational logic of your agent.
- Voice output and text transcripts will diverge in all-in-one models. Plan for it. Don’t trust the logs to match the user experience.
- Voice AI infrastructure is different than traditional text-first. Solved things like load balancing don’t work out of the box anymore.
Bonus Lesson
Voice AI is still emergent tech; the tooling is evolving rapidly, and the patterns are still being defined. But that’s exactly why now is the time to build, while the space is still figuring itself out, while there’s still room to discover what actually works.
And honestly? I’m just getting started. Because every time I think I’ve figured out voice agents, I build the next one and discover a whole new set of things I didn’t know existed.
So the most important lesson is: build the thing. Break it. Rebuild it.
Want to experiment with conversational AI? Check out Agora’s Conversational AI Engine and start building. And if you build something that leaves you voicemails at 4 AM, I want to hear about it.







