On October 20, 2025, at 7:11 GMT, a routine technical update to Amazon Web Services’ DynamoDB API triggered a cascading failure that disrupted over 1,000 businesses and cost an estimated $75 million per hour in lost productivity. Ring doorbells went dark. Venmo transactions failed. Teachers couldn’t access Canvas. Hospital communications systems went offline.
Conversely, applications built on Agora’s Software-Defined Real-Time Network kept running. Video calls continued, live streams didn’t buffer, and interactive broadcasts carried on without interruption. Not because we got lucky, but because our architecture was designed to avoid this kind of failure.
The outage lasted over twelve hours. The root cause? A DNS error at AWS’s US-EAST-1 data center in northern Virginia, triggering cascading failures across 142 services. What followed demonstrated why architectural decisions made years before a crisis matter more than reactive engineering during one.
When Real-Time Communication Fails
For most web services, an outage is an inconvenience. For real-time communication platforms, it’s existential. When you’re in a video consultation with your doctor or teaching remotely, every second of disruption isn’t poor user experience; it’s time you can never get back. This is why real-time communication services demand what telecom operators call “carrier-grade quality”: 99.999% uptime, or 5.26 minutes of downtime per year. Not twelve hours.
Three Architectural Vulnerabilities
Most cloud providers operate on a hub-and-spoke model: resources centralized in massive data centers, then distributed through edge locations. For real-time communication, this creates risk. When two people in Tokyo have a video call, their media shouldn’t route through Virginia.
The AWS outage exposed three vulnerabilities:
Geographic Concentration Risk. AWS’s US-EAST-1 in northern Virginia is a concentration point for global internet infrastructure. When it experiences issues, the impact radiates globally. Services with no physical presence in Virginia still failed because they relied on AWS services that depended on resources in that region.
Single-Network Dependency. Cloud providers route customer traffic through their own private networks. During the outage, when the DNS failure cascaded through AWS’s internal network, there was no alternative path. Unlike the public internet’s BGP protocol, thatwhich reroutes around failing network segments, services were architecturally bound to wait for AWS to fix theirits network.
Cascading Dependency Failures. The initial DNS issue with DynamoDB triggered secondary failures in EC2 instance launches, which caused Network Load Balancer health check failures, cascading into Lambda, CloudWatch, and dozens more. By the end, 142 services had experienced degradation.
Why Others Couldn’t Escape
One real-time video platform couldn’t even log into theiro its own status page to communicate with customers — their provider’s failure locked them out. Even with geographic redundancy across multiple AWS regions, they had to preemptively fail over US traffic to the West Coast, increasing latency for East Coast users. This is the challenge with single-vendor dependency: no matter how well you architect your application, you’re bounded by your infrastructure provider’s reliability ceiling. Multi-region isn’t the same as multi-vendor.
Multi-Vendor by Design
While the AWS outage unfolded, Agora’s network monitoring showed no service degradation. Applications streaming live video to millions of concurrent users experienced zero disruption. Not because we don’t use cloud infrastructure — we do — but because we architected from day one assuming any single vendor dependency is unacceptable risk.
This isn’t about AWS being unreliable. It’s recognition that any single point of dependency, no matter how robust, eventually fails. For services where interruption wastes people’s irreversible time, “eventually” is too often.
Edge-to-Edge Architecture
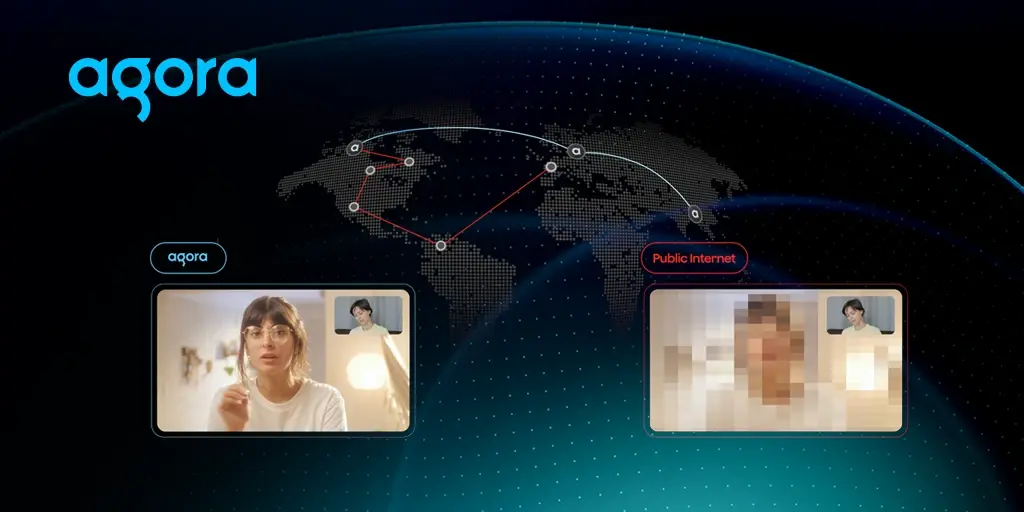
Agora’s Software-Defined Real-Time Network (SDRTN®) consists of globally distributed points of presence, each serving dual purposes: as an access point for nearby users and as a node in our global mesh network. Rather than routing Tokyo-to-Tokyo calls through Virginia, users connect to regional infrastructure and media streams follow optimized paths between these points. When us-east-1 goes down, it doesn’t matter to our Tokyo users. Their traffic never depended on Virginia.
SDRTN® doesn’t avoid single points of failure — it actively leverages path diversity. By default, Agora sends redundant data through the three most optimized network paths simultaneously. The first packet to arrive is used; late or lost packets are discarded. For real-time communication, path redundancy is trivial compared to a dropped doctor’s appointment.
The result: packet loss rates of 0.5% or less, — ten to several hundred times better than best-effort public internet routing, — measured across billions of minutes monthly.
SDRTN® POPs maintain full mesh communication, continuously measuring performance on every possible path through the global network. When congestion emerges, SDRTN® routes around it in real- time. On October 20, while services dependent on US-EAST-1 waited for Amazon to restore operations, SDRTN® automatically rerouted traffic through alternative paths. No emergency failovers. No manual intervention.
Agora has maintained zero system-wide downtime. Individual POPs experience issues — hardware fails, network links have problems, data centers have power events — but the architecture ensures local failures don’t cascade into service degradation because the network automatically reroutes around problems within milliseconds.
The Business Imperative
For real-time communication platforms, outages don’t just lose cost revenue — they lose trust. When your telehealth service fails during a therapy session or your remote learning platform drops during an exam, users remember. They switch to competitors who were online when you weren’t.
Users don’t distinguish between “oh, their cloud provider failed” and “their service failed.” Phone networks are designed with multiple layers of redundancy because a dropped emergency call isn’t acceptable.
The Path Forward
Cloud centralization brought lots of benefits: lower costs, easier scaling, abstracted complexity. But the outage revealed the hidden cost. When three companies control 60% of global cloud services, we’ve created new categories of systemic risk.
For real-time communication services where quality directly impacts human interaction, accepting this risk is untenable. Carrier-grade quality remains the appropriate standard: design for five nines of availability, architect to eliminate single points of failure, measure performance at high percentiles rather than averages.
This philosophy guided SDRTN®’s design from inception. Operating our own global network of POPs, implementing intelligent multi-path routing — we’ve created infrastructure that matches carrier-grade reliability standards at internet scale.
While AWS-dependent services struggled and competitors scrambled to post status updates, applications built on Agora kept working. Not because we got lucky, but because architectural decisions made years ago proved their value when it mattered.
The result is that developers can trust their users’ time won’t be wasted by service interruptions. Doctor consultations won’t drop mid-conversation. Business negotiations won’t freeze. Remote learning experiences won’t fail when students need them most.
When Amazon’s engineers resolved the outage after twelve hours and 50 minutes, they acknowledged that dependencies created cascading failures that no amount of reactive engineering could prevent once triggered. The lesson isn’t that AWS is unreliable — Amazon employs some of the world’s best infrastructure engineers. The lesson is that any architecture with single points of dependency creates risk that real-time communication services can’t afford.
Humans relying on these systems deserve better. They deserve systems designed from the foundation for independence, not retrofitted with redundancy as an afterthought. That’s the philosophy that guided SDRTN®’s design. And on October 20, during twelve hours when large swaths of the internet went dark, that philosophy made the difference between applications that failed and applications that kept running.
For more technical details on SDRTN® architecture and performance benchmarks, visit Agora’s technical documentation or contact our solutions engineering team.







