2025년 10월 20일 GMT 기준 오전 7시 11분, 아마존 웹 서비스(AWS)의 DynamoDB API에 대한 정기 기술 업데이트가 연쇄적인 장애를 유발하여 1,000개 이상의 기업에 차질을 빚었고, 시간당 약 7,500만 달러의 생산성 손실을 초래했습니다. 링(Ring) 도어벨이 작동하지 않았고, 벤모(Venmo) 거래가 실패했으며, 교사들은 캔버스(Canvas)에 접속할 수 없었고, 병원 통신 시스템은 오프라인 상태가 되었습니다.
반면, 아고라(Agora)의 소프트웨어 정의 실시간 네트워크(Software-Defined Real-Time Network)를 기반으로 구축된 애플리케이션들은 계속 작동했습니다. 화상 통화는 이어졌고, 라이브 스트리밍은 버퍼링 없이 진행되었으며, 양방향 방송도 중단 없이 계속되었습니다. 이는 우연이 아니라, 이러한 종류의 장애를 방지하도록 설계된 아키텍처 덕분이었습니다.
정전은 12시간 넘게 지속되었습니다. 근본 원인은 무엇이었을까요? 버지니아 북부에 위치한 AWS의 US-EAST-1 데이터 센터에서 발생한 DNS 오류로, 이로 인해 142개 서비스에 걸쳐 연쇄적인 장애가 발생했습니다. 이후의 상황은 위기 발생 당시의 대응형 엔지니어링보다 수년 전 내린 아키텍처 결정이 왜 더 중요한지를 여실히 보여주었습니다.
실시간 통신이 중단될 때
대부분의 웹 서비스에서 정전은 단순한 불편함일 뿐입니다. 하지만 실시간 통신 플랫폼에 있어서는 생존을 위협하는 문제입니다. 의사와 화상 상담을 하거나 원격 수업을 진행할 때, 단 1초의 중단도 단순히 사용자 경험의 저하가 아닙니다. 그것은 결코 되찾을 수 없는 시간입니다. 이것이 바로 실시간 통신 서비스가 통신 사업자들이 말하는 “캐리어급 품질”을 요구하는 이유입니다. 즉, 99.999%의 가동률, 즉 연간 5.26분의 다운타임을 의미합니다. 12시간이 아닙니다.
세 가지 아키텍처 취약점
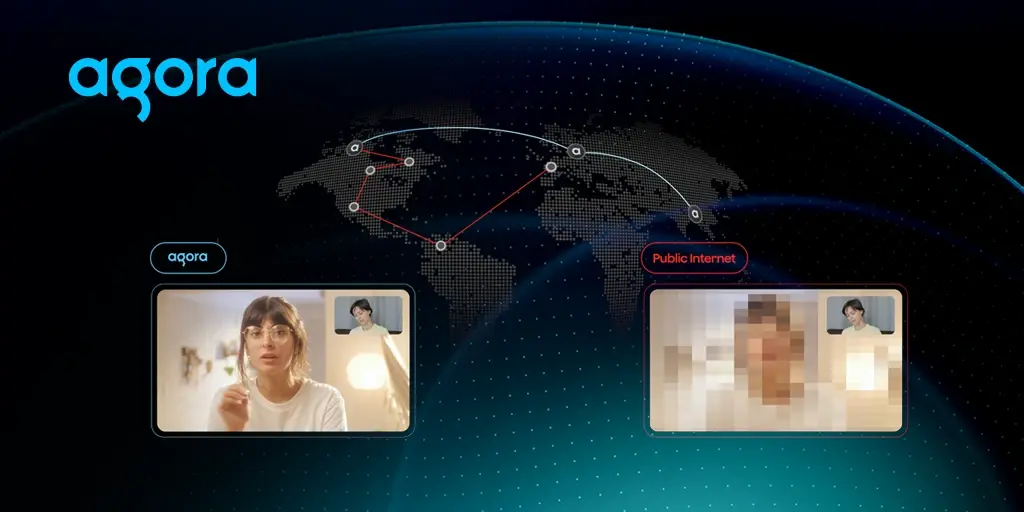
대부분의 클라우드 제공업체는 허브 앤 스포크(hub-and-spoke) 모델로 운영됩니다. 즉, 자원을 대규모 데이터 센터에 중앙 집중화한 후 엣지(edge) 위치로 분산시키는 방식입니다. 실시간 통신의 경우, 이는 위험 요소가 됩니다. 도쿄에 있는 두 사람이 화상 통화를 할 때, 그들의 미디어 트래픽이 버지니아를 경유해서는 안 됩니다.
이번 AWS 서비스 중단 사태는 세 가지 취약점을 드러냈습니다:
지리적 집중 위험. 버지니아 북부에 위치한 AWS의 US-EAST-1은 글로벌 인터넷 인프라의 집중 지점입니다. 이곳에 문제가 발생하면 그 영향은 전 세계로 파급됩니다. 버지니아에 물리적 인프라가 없는 서비스조차도 해당 지역의 리소스에 의존하는 AWS 서비스를 이용하고 있었기 때문에 중단되었습니다.
단일 네트워크 의존성. 클라우드 제공업체는 고객 트래픽을 자체 사설 네트워크를 통해 라우팅합니다. 서비스 중단 기간 동안 DNS 장애가 AWS 내부 네트워크를 통해 연쇄적으로 확산되었을 때, 대체 경로는 존재하지 않았습니다. 장애가 발생한 네트워크 구간을 우회하는 공용 인터넷의 BGP 프로토콜과 달리, 서비스들은 아키텍처상 AWS가 네트워크를 복구할 때까지 기다릴 수밖에 없었습니다.
연쇄적인 의존성 장애. DynamoDB의 초기 DNS 문제는 EC2 인스턴스 시작에 2차 장애를 유발했고, 이는 Network Load Balancer 상태 확인 실패로 이어져 Lambda, CloudWatch 및 수십 개의 다른 서비스로 연쇄적으로 확산되었습니다. 결국 142개 서비스가 성능 저하를 겪었습니다.
다른 업체들도 피할 수 없었던 이유
한 실시간 비디오 플랫폼은 고객과 소통하기 위해 자사의 상태 페이지에 접속조차 할 수 없었습니다. 공급자의 장애로 인해 접속이 차단된 것입니다. 여러 AWS 리전에 걸친 지리적 중복성을 갖추고 있었음에도 불구하고, 미국 트래픽을 서부 해안으로 선제적으로 전환해야 했으며, 이로 인해 동부 해안 사용자의 지연 시간이 증가했습니다. 이것이 단일 공급업체 의존성의 문제점입니다. 애플리케이션을 아무리 훌륭하게 설계하더라도, 인프라 공급업체의 신뢰성 한계에 얽매이게 됩니다. 다중 리전은 다중 공급업체와 같지 않습니다.
설계 단계부터 다중 공급업체 채택
AWS 장애가 진행되는 동안, Agora의 네트워크 모니터링에는 서비스 성능 저하가 전혀 나타나지 않았습니다. 수백만 명의 동시 사용자에게 라이브 비디오를 스트리밍하는 애플리케이션은 단 한 번의 중단도 경험하지 않았습니다. 이는 우리가 클라우드 인프라를 사용하지 않기 때문이 아닙니다. 우리는 클라우드 인프라를 사용합니다. 하지만 우리는 첫날부터 단일 공급업체 의존은 용납할 수 없는 위험이라는 전제 하에 아키텍처를 설계했기 때문입니다.
이는 AWS가 신뢰할 수 없다는 의미가 아닙니다. 아무리 견고하더라도 모든 단일 의존 지점은 결국 실패한다는 사실을 인식한 것입니다. 중단이 사람들의 되돌릴 수 없는 시간을 낭비하게 만드는 서비스의 경우, '결국'이라는 말은 너무 빈번하게 발생합니다.
엣지-투-엣지 아키텍처
아고라(Agora)의 소프트웨어 정의 실시간 네트워크(SDRTN®)는 전 세계에 분산된 접속 지점(PoP)으로 구성되어 있으며, 각 지점은 인근 사용자를 위한 접속 지점이자 글로벌 메시 네트워크의 노드라는 두 가지 역할을 수행합니다. 도쿄에서 도쿄로 걸리는 통화를 버지니아를 경유해 라우팅하는 대신, 사용자는 지역 인프라에 연결되며 미디어 스트림은 이러한 지점들 사이의 최적화된 경로를 따라 전송됩니다. us-east-1이 다운되더라도 도쿄 사용자에게는 아무런 영향이 없습니다. 그들의 트래픽은 애초에 버지니아에 의존하지 않았기 때문입니다.
SDRTN®은 단일 장애 지점을 피하는 것이 아니라 경로 다양성을 적극적으로 활용합니다. 기본적으로 아고라는 가장 최적화된 세 개의 네트워크 경로를 통해 중복 데이터를 동시에 전송합니다. 가장 먼저 도착한 패킷이 사용되며, 늦게 도착하거나 손실된 패킷은 버려집니다. 실시간 통신에서 경로 중복성은 의사 진료 예약을 놓치는 것에 비하면 사소한 문제입니다.
그 결과: 매월 수십억 분에 걸쳐 측정된 패킷 손실률은 0.5% 이하로, 베스트 이포트(best-effort) 방식의 공용 인터넷 라우팅보다 10배에서 수백 배 더 우수합니다.
SDRTN® POP(접속점)은 풀 메쉬(full mesh) 통신을 유지하며, 글로벌 네트워크를 통과하는 모든 가능한 경로의 성능을 지속적으로 측정합니다. 혼잡이 발생하면 SDRTN®은 이를 실시간으로 우회합니다. 10월 20일, US-EAST-1에 의존하는 서비스들이 아마존의 운영 복구를 기다리는 동안, SDRTN®은 자동으로 대체 경로를 통해 트래픽을 재라우팅했습니다. 비상 페일오버도, 수동 개입도 필요하지 않았습니다.
아고라는 시스템 전체 다운타임을 단 한 번도 발생시키지 않았습니다. 개별 POP에서는 하드웨어 고장, 네트워크 링크 문제, 데이터 센터의 전력 장애와 같은 문제가 발생하기도 하지만, 네트워크가 문제 발생 시 밀리초 단위로 자동으로 우회 경로를 설정하므로 아키텍처 덕분에 로컬 장애가 서비스 품질 저하로 이어지는 연쇄 반응을 일으키지 않습니다.
비즈니스의 필수 요건
실시간 통신 플랫폼의 경우, 서비스 중단은 단순히 수익 손실을 초래할 뿐만 아니라 신뢰까지 잃게 만듭니다. 치료 세션 중에 원격 의료 서비스가 중단되거나 시험 중에 원격 학습 플랫폼이 다운되면 사용자들은 이를 기억합니다. 그들은 여러분이 서비스를 제공하지 못했을 때 정상적으로 운영되던 경쟁사로 갈아타게 됩니다.
사용자는 “아, 그 회사의 클라우드 제공업체에 문제가 생겼구나”와 “그 회사의 서비스가 중단되었구나”를 구분하지 않습니다. 전화망은 긴급 전화가 끊기는 것을 용납할 수 없기 때문에 다중 중복 계층으로 설계됩니다.
앞으로 나아갈 길
클라우드 중앙화는 비용 절감, 쉬운 확장성, 복잡성 추상화 등 많은 이점을 가져왔습니다. 하지만 이번 서비스 중단은 숨겨진 비용을 드러냈습니다. 세 기업이 전 세계 클라우드 서비스의 60%를 장악하게 되면서, 우리는 새로운 유형의 체계적 위험을 만들어냈습니다.
품질이 인간 상호작용에 직접적인 영향을 미치는 실시간 통신 서비스의 경우, 이러한 위험을 감수하는 것은 용납될 수 없습니다. 캐리어급 품질이 여전히 적절한 기준입니다: 99.999%의 가용성을 목표로 설계하고, 단일 장애 지점을 제거하도록 아키텍처를 구성하며, 평균이 아닌 상위 백분위수 기준으로 성능을 측정해야 합니다.
이러한 철학은 SDRTN®의 설계 초기부터 지침이 되었습니다. 자체 글로벌 POP 네트워크를 운영하고 지능형 다중 경로 라우팅을 구현함으로써, 우리는 인터넷 규모에서 캐리어급 신뢰성 기준에 부합하는 인프라를 구축했습니다.
AWS에 의존하는 서비스들이 어려움을 겪고 경쟁사들이 상태 업데이트를 올리기 위해 분주하던 동안, 아고라(Agora)를 기반으로 구축된 애플리케이션들은 계속 작동했습니다. 이는 우연이 아니라, 수년 전 내린 아키텍처적 결정들이 중요한 순간에 그 가치를 입증했기 때문입니다.
그 결과 개발자들은 서비스 중단으로 인해 사용자의 시간이 낭비되지 않을 것이라고 확신할 수 있습니다. 의사와의 상담이 대화 도중에 끊어지지 않을 것입니다. 비즈니스 협상이 중단되지 않을 것입니다. 학생들이 가장 필요로 할 때 원격 학습이 실패하지 않을 것입니다.
아마존 엔지니어들이 12시간 50분 만에 장애를 해결했을 때, 그들은 의존성이 연쇄적인 장애를 유발했으며, 일단 발생하면 아무리 대응적인 엔지니어링으로도 막을 수 없었다고 인정했습니다. 이 사건에서 얻을 수 있는 교훈은 AWS가 신뢰할 수 없다는 것이 아닙니다. 아마존은 세계 최고 수준의 인프라 엔지니어들을 고용하고 있습니다. 진정한 교훈은 단일 의존 지점을 가진 어떤 아키텍처라도 실시간 통신 서비스가 감당할 수 없는 위험을 초래한다는 점입니다.
이러한 시스템에 의존하는 사람들은 더 나은 대우를 받을 자격이 있습니다. 그들은 사후적으로 중복성을 덧씌운 것이 아니라, 독립성을 기반으로 설계된 시스템을 누릴 자격이 있습니다. 이것이 바로 SDRTN®의 설계를 이끈 철학입니다. 그리고 10월 20일, 인터넷의 광범위한 영역이 12시간 동안 마비되었던 그 순간, 바로 이 철학이 실패한 애플리케이션과 계속 작동한 애플리케이션의 차이를 만들어냈습니다.
SDRTN® 아키텍처 및 성능 벤치마크에 대한 더 자세한 기술 정보는 아고라의 기술 문서를 참조하거나 솔루션 엔지니어링 팀에 문의해 주십시오.







