视频图像合并听起来好像很难理解,其实直观的可以理解成画中画,记得我第一次有印象还是电视节目画中画,可以在观看一个频道节目时,一个小窗口展示上|下一个频道的节目,当时觉得有点玄乎,现在应用已经相当普遍了;基本原理就是将多个视频/图像按照不同位置叠放在一起,达到用户看到画中画的感觉。
我们以视频会议场景为例描述下视图合并的实现方式,在视频会议架构中,采集+编码由演讲者所在终端负责,解码+渲染都是观看者所在终端负责,会议会话管理以及视频流量转发则是由服务器端负责(由于要多人观看,而不是一对一通话),示例图如下
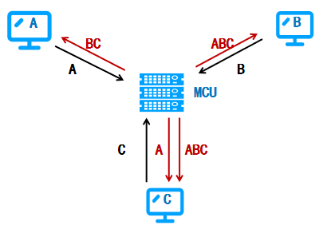
视频流转流程是经过采集-编码-传输-解码-显示,如下

视频图像合并的处理由服务端到终端侧即由云侧到端侧演进,当前是两种实现并存,端侧实现又分为两种(一种在采集端实现,一种在播放端实现);伴随着移动互联网的繁荣,网络带宽的大幅提升和使用成本下降,也得益于终端侧处理能力逐步提升,视图合并的处理基本已经由Server端转向由终端实现,这样在使用者的PC/手机/Pad/固定会议终端上就完成视频图像处理,对于Server端处理压力大大减轻。
伴随着视频业务的繁荣发展,对于视图合并的需求也在持续的增加,从最初视频会议的参会者混屏多画面,到现在众多应用,举例:
- 疫情封控,公司视频会议年会,北京、上海、深圳三地团队互动,云游戏,云聚餐
- 展会/论坛/课程直播,一边播放着教材PPT,一边老师在声情并茂、耐心细致的讲解
- 直播带货,一边主播在视频里展示商品,通话画面变换着商品链接,点击购买(又囤货了,还好有了过期自动退)
声网的视图合并功能,集成在WebSDK中,提供可比较丰富的功能接口,可以基于摄像头采集视频、共享通道视频、图片进行视图合并。
本文参考Web SDK实现视图合并功能,增加在渲染端叠加的应用
- 在采集端叠加摄像头和图片,可以想象成在做课程PPT培训时添加讲师画面和公众号二维码
- 在渲染端叠加图片,可以认为是安全提示,按照与会者信息叠加水印图片
实现后效果如下:
(1) 开发环境,笔记本/台式电脑和有效的Agora账号即可,浏览器我用的是Chrome(Version 111.0.5563.147);安装好nodejs环境,这样才能执行npm install安装
(2) 提前创建好一张二维码图片,背景透明,文字用户名
(3) 采用官网提供的插件引入使用方式进行试用,引入插件
(4) 采集端代码部分:
const LiveStreamClient = AgoraRTC.createClient({mode: "rtc", codec: "h264"});
const LsVcExtension = new VideoCompositingExtension();
let LsVCompositor = LsVcExtension.createProcessor();
LocScreenShareTrack = await AgoraRTC.createScreenVideoTrack({encoderConfig: {frameRate: 15}});
LocVideoTrack = await AgoraRTC.createCameraVideoTrack({cameraId: videoSelect.value, encoderConfig: 'cif'})
const LocSSEndpoint = LsVCompositor.createInputEndpoint({x: 0, y: 0, width: 1920, height: 1080, fit: 'cover'});
const LocVCEndpoint = LsVCompositor.createInputEndpoint({x: 2140, y: 240, width: 352, height: 288, fit: 'cover'});
LocScreenShareTrack.pipe(LocSSEndpoint).pipe(LocScreenShareTrack.processorDestination);
LocVideoTrack.pipe(LocVCEndpoint).pipe(LocVideoTrack.processorDestination);
const LSCanvas = document.createElement('canvas');
LSCanvas.getContext('2d');
let LocLSTracks = {
videoTrack: null,
audioTrack: null,
};
LocLSTracks.videoTrack = AgoraRTC.createCustomVideoTrack({ mediaStreamTrack: LSCanvas.captureStream().getVideoTracks()[0]});
LsVPCompositor.addImage('./mocromsg_qrencode.jpg', {x: 2140, y: 1080, width: 240, height: 240, fit: 'cover'})
LsVCompositor.setOutputOptions(2560, 1440, 15);
// 开始合图
await LsVCompositor.start();
// 将合图后的视频注入本地视频轨道
LocLSTracks.videoTrack.pipe(LsVCompositor).pipe(LocLSTracks.videoTrack.processorDestination);
// 播放和发布本地音视频轨道
LocLSTracks.videoTrack.play("local-player");
LocLSTracks.audioTrack = LocLSTracks.audioTrack || await AgoraRTC.createMicrophoneAudioTrack();
await LiveStreamClient.publish(Object.values(LocLSTracks));(5) 渲染端代码部分:
提前创建好一张文字图片,背景透明,文字用户名
const WMClient = AgoraRTC.createClient({mode: "rtc", codec: "h264"});
const LsVcExtension = new VideoCompositingExtension();
let LsVPCompositor = LsVcExtension.createProcessor();
LsVPCompositor.addImage('./assets/watermark.jpg', {x: 0, y: 0, width: 1280, height: 720, fit: 'cover'})
LsVPCompositor.setOutputOptions(1280, 720, 15);
await LsVPCompositor.start();
let LocPlayTracks = {
videoTrack: null,
audioTrack: null,
};
WMClient.on("user-published", async (user, mediaType) => {
// 发起订阅
await WMClient.subscribe(user, mediaType);
// 如果订阅的是音频轨道
if (mediaType === "audio") {
const UserAudioTrack = user.audioTrack;
audioTrack.play();
} else {
const UserVideoTrack = user.videoTrack;
LocPlayTracks.videoTrack = AgoraRTC.createCustomVideoTrack({ mediaStreamTrack: UserVideoTrack});
LocPlayTracks.videoTrack.pipe(LsVPCompositor).pipe(LocPlayTracks.videoTrack.processorDestination);
LocPlayTracks.videoTrack.play(DOM_ELEMENT);
}
});相对比,server端实现存在显而易见的弊端,针对成千上万的用户以及需求,需要在server部署处理性能极强的大量设备,而且需要随着用户的增长持续膨胀,这对服务提供方无论建设、开发以及维护成本都是难以持续演进的;另外对于客户特有信息特性的扩展支持也非常不灵活。
至于是在采集端进行视图合并,还是在渲染端采用视图合并,是跟具体的应用场景相关的,像直播带货场景,应该是在采集端进行合并最合理;而对于多地视频会议混屏,则应该是在渲染端进行;而假设共享PPT的同时需要观看演讲者的视频,由于是全球大会,需要给不同国家的观看者显示不同语言的文字信息,此时采集端和渲染端的合并需要同时使用。
当然在端侧处理也不都是优点,所谓有人欢喜有人忧,对于用户和运营方是非常方便的,但是对于产品提供方和开发人员就困难很大,原因主要是当前终端侧有非常多显示方式,APP、WEB,APP又有多种编程语言、以及运行于多种CPU架构以和操作系统,光ARM就有ArmV7-ArmV8,ArmV7又包含armv7-A 对应 cortex-A5~A15处理器,armv7-R 对应 cortex-R4~R7 处理器,armv7-M 对应 cortex-M3、M4 处理器,........等好多不同的指令集,还好我在声网基本在找到了我所使用的平台SDK。
总之,对于视频应用提供方和使用方,视图合并对于丰富不同业务应用给出了有力的技术支持,使得应用越来越便捷,体验越来越丰富。