


最近,GitHub Docs 将其站内搜索改成了 Elasticsearch。本文主要介绍 Elasticsearch 的实现方式。
在此之前,GitHub Docs 的站内搜索是一种内存解决方案,但我们需要一个能跟随需求增长而扩展的解决方案,因此我们写了 Elasticsearch。本文我们将教大家实现 Elasticsearch,让用户喜欢上你的站内搜索。
开始
按照之前的解决方案,所有的记录都要加载到内存中(Express.js 运行的 Node.js 代码),所以无法扩展。这个解决方案则要抓取所有可搜索的文本(包括标题、标头、面包屑、内容等),将这些数据存储在特定位置,以便数据在 Node 进程运行时中快速加载。我们使用 Git 版本库来存储这些数据,这样,当在 Azure 中构建 Docker 镜像运行时,它可以访问磁盘上所有的可搜索文本。
因为加载所有可搜索文本需要时间,所以我们在搜索文本中生成一个序列化索引,并将该序列化索引也存储至磁盘。如果数据不大,这个解决方案就是可行的,问题是我们的数据是八种语言,而且每种语言还有五个不同版本。
在本地运行 Elasticsearch
选择 Elasticsearch 的缘由很多,我会在之后的文章中详述。这里只说关键的一点——Elasticsearch 可以在笔记本电脑上本地运行,因此,我们的大多数贡献者不用安装 Elasticsearch。默认状态下,我们的 /api/search Express.js 中间件如下:
if (process.env.ELASTICSEARCH_URL) {
router.use('/search', search)
} else {
router.use(
'/search',
createProxyMiddleware({
target: 'https://docs.github.com',
...用户在笔记本电脑(或 Codespaces)上点开 http://localhost:4000/api/search 时,该链接会将 Elasticsearch 的内容转发给我们的生产服务器,然后,我们在本地调试搜索引擎的工程师(比如我)就可以在 http://localhost:9200 启动一个 Elasticsearch,并在 .env 文件中对 Elasticsearch 进行设置,这样,工程师就可以使用本地端的 Elasticsearch 快速试用新的搜索查询技术。
搜索的实现
我们的搜索实现的核心理念是——只向 Elasticsearch 发出一个查询,其中包含我们想要的结果排序规范。相较于发送单一的请求,我们可以先尝试更具体的搜索查询,如果获得的结果太少,就再进行第二次不太明确的搜索查询:
// NOTE! This is NOT what we do.
let result = await client.search({ index, body: searchQueryStrict })
if (result.hits.length === 0) {
// nothing found when being strict, try again with a loose query
result = await client.search({ index, body: searchQueryLoose })
}为确保获得最精确的结果,我们使用了 boost 和多种匹配技术的矩阵,代码如下:
如果查询的是多个术语:
[
{ match_phrase: { title_explicit: [Object] } },
{ match_phrase: { title: [Object] } },
{ match_phrase: { headings_explicit: [Object] } },
{ match_phrase: { headings: [Object] } },
{ match_phrase: { content: [Object] } },
{ match_phrase: { content_explicit: [Object] } },
{ match: { title_explicit: [Object] } },
{ match: { headings_explicit: [Object] } },
{ match: { content_explicit: [Object] } },
{ match: { title: [Object] } },
{ match: { headings: [Object] } },
{ match: { content: [Object] } },
{ match: { title_explicit: [Object] } },
{ match: { headings_explicit: [Object] } },
{ match: { content_explicit: [Object] } },
{ match: { title: [Object] } },
{ match: { headings: [Object] } },
{ match: { content: [Object] } },
{ fuzzy: { title: [Object] } }
]如果查询的是单一术语:
[
{ match: { title_explicit: [Object] } },
{ match: { headings_explicit: [Object] } },
{ match: { content_explicit: [Object] } },
{ match: { title: [Object] } },
{ match: { headings: [Object] } },
{ match: { content: [Object] } },
{ fuzzy: { title: [Object] } }
]查询多次看似很麻烦,但 Elasticsearch 的速度非常快。实际上,发送查询和接收结果花费了大部分时间,而 Elasticsearch 服务器执行搜索查询的总时间(不考虑网络因素)稳定在 20 毫秒。
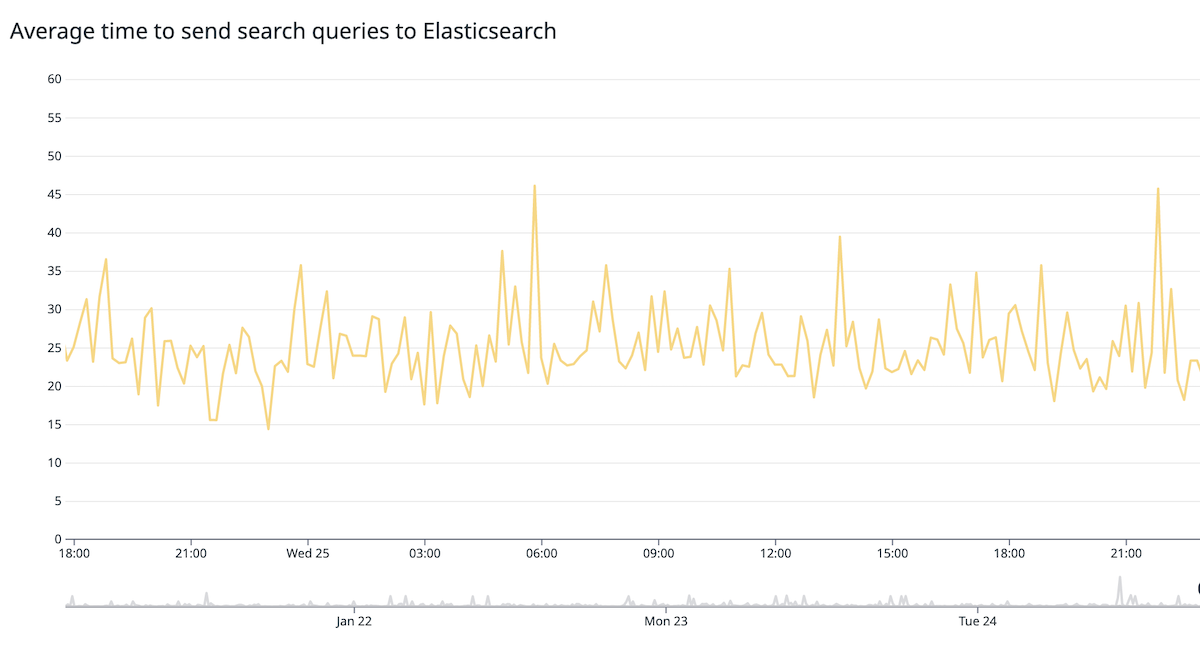
docs.github.com 上的所有搜索中的 55% 是多词查询,例如,actions rest。换句话说,一半情况下,我们可以使用简化查询,省去查询中的 match_phrase 部分。
在讨论各种搜索组合之前,我们要先讨论一下“明确”的意思。基本上,每个字段都被索引了两次。例如,title 和 title_explicit。这两个词内容相同,但标记不同,它与查询的匹配方式就不同,这种差异可以通过不同的 boost 来利用。
构成矩阵的节点是:
Fields:
- title (h1 文本)
- headings (h2 文本)
- content (正文的主干)
Analyzer:
- 明确 (没有词根和同义词)
- 常规(完整的雪球词干,可能还有同义词)
Matches: (多术语查询)
- match_phrase
- match with OR (包含 “foo” 或 “bar”的文档)
- match with AND (包含 “foo” 和 “bar”的文档)
每个组合都有一个独特的 boost 数字,可以提升匹配到的结果的排名。具体是什么数字并不重要,重要的是这些 boost 数字各不相同。例如,title 匹配比 content 匹配的 boost 数字略高;所有词都出现的匹配比只有部分词匹配时的 boost 数字略高。还有,如果搜索词是 docker action,用户更想看到“Creating a Docker container action”,而不是 “Publishing Docker images” 或 “Metadata syntax for GitHub Actions”。
上述每个节点都有一个 boost 计算,如下:
const BOOST_PHRASE = 10.0
const BOOST_TITLE = 4.0
const BOOST_HEADINGS = 3.0
const BOOST_CONTENT = 1.0
const BOOST_AND = 2.5
const BOOST_EXPLICIT = 3.5
...
match_phrase: { title_explicit: { boost: BOOST_EXPLICIT * BOOST_PHRASE * BOOST_TITLE, query } },
match: { headings: { boost: BOOST_HEADINGS * BOOST_AND, query, operator: 'AND' } },
...如果打印出矩阵中每个节点的 boost 值,可以获得下列内容:
[
{ match_phrase: { title_explicit: 140 } },
{ match_phrase: { title: 40 } },
{ match_phrase: { headings_explicit: 105 } },
{ match_phrase: { headings: 30 } },
{ match_phrase: { content: 10 } },
{ match_phrase: { content_explicit: 35 } },
{ match: { title_explicit: 35, operator: 'AND' } },
{ match: { headings_explicit: 26.25, operator: 'AND' } },
{ match: { content_explicit: 8.75, operator: 'AND' } },
{ match: { title: 10, operator: 'AND' } },
{ match: { headings: 7.5, operator: 'AND' } },
{ match: { content: 2.5, operator: 'AND' } },
{ match: { title_explicit: 14 } },
{ match: { headings_explicit: 10.5 } },
{ match: { content_explicit: 3.5 } },
{ match: { title: 4 } },
{ match: { headings: 3 } },
{ match: { content: 1 } },
{ fuzzy: { title: 0.1 } }
]这就是我们发送给 Elasticsearch 的内容,类似一个复杂的愿望清单:“我想要的圣诞礼物是一辆自行车。如果你可以给我一辆粉红色的,那是极好的;如果是印了蓝色条纹的粉色自行车,就更好;如果是印有蓝色条纹的粉色自行车,而且还有一个铜铃,就最好啦!”
就用户的理想实现和搜索结果来说,重点是使用人类的智慧和语境来定义这些参数。这些参数有些很明显,但有些则比较微妙。例如,我们通常认为,标题中 title 匹配且不需要联系词干是最好的匹配,能得到最高的 boost。
为什么明确的 boost 很重要?
如果有人输入“创建版本库”,肯定会与“创建私有 GitHub 版本库”此类标题匹配,因为词干 creating => creat <= create,repositories => repository <= repository。我们一定要把与词干相关的匹配考虑在内。但是,如果一篇文章明确使用了与用户输入内容相匹配的词,比如“创建私人 GitHub 仓库”,我们就要提升这篇文章的排序,因为这个内容更符合搜索者的需求。
另一个更好的例子是是特殊关键词 working-directory,这是一个精确的术语,有可能出现在内容里面。如果用户搜索 working-directory,当 working-directory 和 "Directories that work” 被解构为相同的两个词干 ['work','Directori'] 时,我们一定不想让“Directories that work”之类的标题排在这两者前面。
我们的解决方案是进行两次匹配:一次有词干,一次没有。每一个都有不同的 boost。类似于说:“我正在寻找 'Peter',但如果有 'Petter'、'Pierre' 或 'Piotr' 也行。理想情况下,当然是 'Peter' 最好。给我所有的结果,但最好是 'Peter',这就是我们的解决方案。词根很好用,但可能会“覆盖”搜索结果。这种解决方案有利于处理类似英语散文的特定关键词。例如,“working-directory”看起来像一个常规的英语表达式,但实际上是一个硬编码特定关键词。
下面是代码:
// Creating the index...
await client.indices.create({
mappings: {
properties: {
url: { type: 'keyword' },
title: { type: 'text', analyzer: 'text_analyzer', norms: false },
title_explicit: { type: 'text', analyzer: 'text_analyzer_explicit', norms: false },
content: { type: 'text', analyzer: 'text_analyzer' },
content_explicit: { type: 'text', analyzer: 'text_analyzer_explicit' },
// ...snip...
},
},
// ...snip...
})
// Searching...
matchQueries.push(
...[
{ match: { title_explicit: { boost: BOOST_EXPLICIT * BOOST_TITLE, query } } },
{ match: { content_explicit: { boost: BOOST_EXPLICIT * BOOST_CONTENT, query } } },
{ match: { title: { boost: BOOST_TITLE, query } } },
{ match: { content: { boost: BOOST_CONTENT, query } } },
// ...snip...
])排序并不容易
搜索越来越重要了。仅仅匹配术语,显示一个与输入术语相匹配的文件列表是不够的。对于新手来说,搜索结果的排序至关重要。当一个搜索词产生几十上百个匹配的结果时,这一点尤其重要。多年来我们都喜欢使用谷歌搜索引擎,所以都期望检索出来的第一个结果就是我们想要的。
为了保证用户的站内搜索体验,我们尝试使用页面浏览量指标来推断用户真正在寻找的文件,由此确定最受用户欢迎的页面。当然,先提供页面,这个页面就会获得用户点击量,就会变得更受欢迎。我们从用户搜索的内容里获得大量的页面浏览量,用户只是简单地浏览他们自己感兴趣的页面,我们就可以得到很多常规的浏览量指标。
目前,我们收集了前 1000 个最受欢迎的 URL 页面浏览量指标。然后对它们进行排序,将其规范化为一个介与(包括)0.0 到 1.0 之间的数字。不管这个数字是多少,我们都要加上 +1.0,然后在 Elasticsearch 中把这个数字与匹配分数相乘。
假设一个搜索查询找到了两个匹配的文档,根据上面提到的搜索实现,它们的匹配分数分别是 15.6 和 13.2。现在,假设 13.2 的那个匹配是在一个受欢迎的页面上,它的受欢迎程度可能是 0.75,最终结果就是 13.2*(1+0.75)=23.1。而另一个匹配度稍好的受欢迎程度为 0.44,所以它的最终结果就是 15.6 * (1 + 0.44) = 22.5,这个数字较小,就给了那些不像其他文件那样“匹配”的文件一个提升的机会。这也确保了在内容上只是模糊匹配的文件不会“覆盖”其他标题匹配的文件。
这非常有挑战性,同时也很有趣味。我们必须在代码中加入一些人类的思维,试着从用户的角度来思考。这不是一个完美的算法,即使其他更多更好的指标,用户的想法都在不断变化,我们要随时了解用户的想法。
下一步
Elasticsearch 有一个功能,可以为单词定义别名,称之为同义词(例如,repo = repository)。这个功能的难点在于写作者如何对其进行管理和维护。
目前, GitHub的人气数字是基于页面浏览量的指标。如果能更深入地挖掘用户查看的页面,就更有意思了。比如,假设读者不知道如何找到自己需要的东西,他们就需要从产品登陆页面开始(我们有大约 20 个这样的页面),慢慢深入内容,直到最后找到他们所需的知识或答案的页面。这个过程给每个页面衡量标准是一样的,不是很好。
另一个办法是记录所有没有点击搜索结果 URL 的时间,特别是当它在排序更高时。这样可以避免受欢迎的列表更受欢迎这个不良循环。如果你记录到一些被用户“纠正”的内容,可能会是一个非常有力的证明。
你还可以根据其他上下文变量来定制基础搜索。例如,如果用户目前在 REST API 文档内,就可以推断出在搜索像“计费”这样模棱两可的东西时,RESTAPI 相关的文档会更受欢迎 (即 REST API “关于计费”,而不是“计费和支付”或“设置你的计费电子邮件”)。
你接下来想检索什么呢?最近是否使用过 https://docs.github.com?它是否给你提供了最合适的搜索结果?如果没有,欢迎随时与我们联系。
原文作者:Peter Bengtsson
原文链接:https://github.blog/2023-03-09-how-github-docs-new-search-works/







