一篇关于聊天机器人 ChatGPT 背后逻辑的简要介绍

本文主要介绍 ChatGPT 背后的机器学习模型,开头首先介绍大型语言模型,然后深入探讨能使 GPT-3 得到训练的自注意力机制,最后研究基于人类反馈的强化学习,正是这些技术促成了ChatGPT 的火爆。
大型语言模型
ChatGPT 是大型语言模型(LLM,一类机器学习自然语言处理模型)的外推。LLM 消化大量的文本数据,并推断出文本中单词之间的关系。近几年,计算能力不断进步,输入数据集和参数空间不断增长,促进了LLM 的发展。
对语言模型最基本的训练包括预测单词序列中的一个词。最常见的是“下一个词预测”(next-token-prediction)和掩码语言建模(masked-language-modeling)。
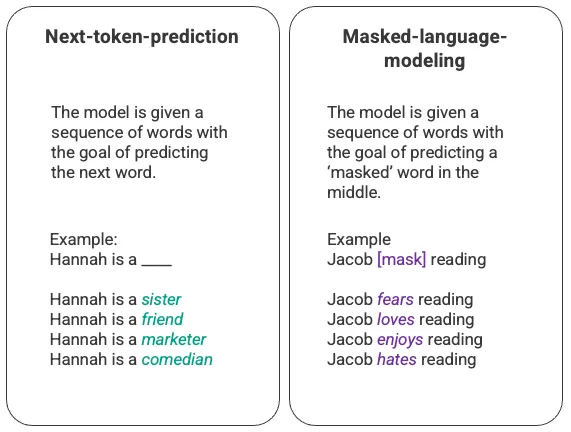
“下一个词预测”和“掩码语言建模”示例
这种基本序列技术通常通过长短期记忆网络(LSTM)模型部署。LSTM 模型可以根据上下文,选择大数据中概率最高的词来填空。但是,这种序列建模结构有两大局限:
- 该模型无法侧重特定的下上文。比如,在上图的例子中,虽然‘reading’ 可能最常与 ‘hates’ 联系在一起,但在数据库中,‘Jacob’ 可能个阅读爱好者,所以,相较于 'reading',模型应该给予 'Jacob' 更多权重,选择 'love' 而不是 'hate'
- 输入的数据不是以一个整体的语料库的形式处理的,而是按照序列逐个处理的。因此,训练 LSTM 时,上下文窗口是固定的,只能在序列的几个步骤中的单个输入间扩展。这就限制了LSTM 模型对词与词之间复杂关系的捕捉,以及对词的含义的延展。
针对这个问题,Google Brain 的一个团队在 2017 年引入了 transformer。与 LSTM 不同,transformer 可以同时处理所有的输入数据。利用自注意力机制,transformer 可以根据语言序列的位置,给予输入数据不同的权重。这一功能在向 LLM 注入意义方面有了巨大的改进,并且可以处理更大的数据集。
GPT 和自注意力
2018 年,OpenAI 首次推出了 Generative Pre-training Transformer(GPT),代号为 GPT-1。随后,在2019年出现了GPT-2,在 2020 年出现了 GPT-3。直到 2002 年出现了 InstructGPT 以及 ChatGPT。在将人类反馈集成到系统之前,GPT 模型演进的最大进步是由计算效率所取得的成就推动的,这让 GPT-3 比 GPT-2 多接收了很多数据用来训练,赋予它更多样化的知识库,以及执行更广泛任务的能力。

GPT-2(左)和 GPT-3(右)的对比
所有的 GPT 模型都利用了 transformer 架构,都分别有一个编码器来处理输入序列,一个解码器来生成输出序列。编码器和解码器都有一个多头的自注意力机制,这种机制可以让模型对序列的不同位置进行加权处理,从而推断含义与上下文。此外,编码器利用掩码语言建模来理解单词之间的关系,并生成更易于理解的响应。
驱动 GPT 的自注意力机制会将标记(文本片段,可以是单词、句子或其他文本组)转换为向量,用来表示标记在输入序列中的重要性。为此,该模型会:
- 为输入序列中的每个标记(token)创建查询向量、键向量和值向量。
- 通过取两个向量的点积(dot product)来计算第一步中的查询向量与每个其他标记的键向量之间的相似度。
- 将第二步计算得到的相似度输入到一个 softmax 函数中,得到一组归一化的权重。
- 将第三步中生成的权重乘以每个标记的值向量,生成一个最终向量,用来表示标记在序列中的重要性。
GPT 采用的“多头”注意力机制是自注意力的优化。上述第一步到第四步不是只执行一次,而是多次迭代,每次都会生成查询向量、键向量以及值向量的新的线性投影。以这种方式扩展自注意力,该模型就可以掌握输入数据的子含义(sub-meanings)以及更复杂的关系。

ChatGPT 的屏幕截图
尽管 GPT-3 在自然语言处理方面有显著的进步,但在满足用户意图方面能力有限。比如,GPT-3 可能会有这样的输出:
- 缺乏用处——不遵循用户的明确指示。
- 含有幻觉——反映不存在的或不正确的事实。
- 缺乏可解释性——人类难以理解模型是如何得出一个特定的决定或预测的。
- 包括有害或偏见的内容——这些内容有害或令人反感,且传播错误信息。
为了解决标准 LLM 的一些固有问题,ChatGPT 引入了创新的训练方法。
ChatGPT
ChatGPT 是 InstructGPT 的衍生品,它的新颖之处在于将人类反馈纳入训练过程,使模型的输出与用户的意图保持一致。2022 年,OpenAI 发表论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),文中介绍了利用人类反馈的强化学习(RLHF),内容如下:
第一步:监督微调(SFT)模型
首先,雇用 40 名承包商,创建一个“有监督训练的数据集”,对 GPT-3 模型进行微调,给模型学习的输入和输出都是已知的。输入(提示)收集的是真实用户对 Open API 的输入。然后,打标签者会对提示做出适当的回应,从而为每个输入创建一个已知的输出,然后再用这个新的监督数据集对 GPT-3 模型进行微调,从而建立起 GPT-3.5,即 SFT 模型。
为尽量保证提示数据集的多样性,所有既定用户 ID 只能提供 200 个提示,并且所有人输入的提示前缀会被删除。最后,所有包含个人身份信息(PII)的提示也会被删除。
汇总了 OpenAI API 的提示后,他们会让打标签人员创建样本提示,去填充只有最少真实样本数据的类别。相关的类别包括:
- 普通提示:任何询问。
- 少样本提示:包含多个查询或响应对的指令。
- 用户提示:类似于为 OpenAI API 请求的特定用例。
生成响应时,打标签者要尽最大努力推断用户的指令是什么。该论文介绍了提示请求信息的三种主要方式:
- 直接:"告诉我……"
- 少样本:根据这个故事的两个例子,再写一个同主题的故事。
- 延续:给出故事开头,续写故事。
根据 OpenAI API 和打标签人员手写的提示,总共得出了 13000 个输入/输出样本,部署到该“有监督模型”上。
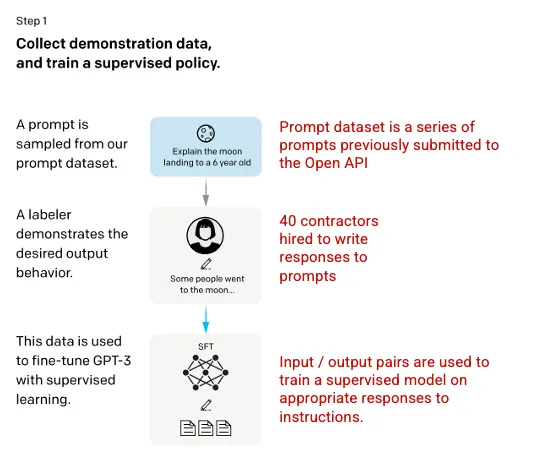
图片(左)插入自训练语言模型以遵循人类反馈的指令 OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf
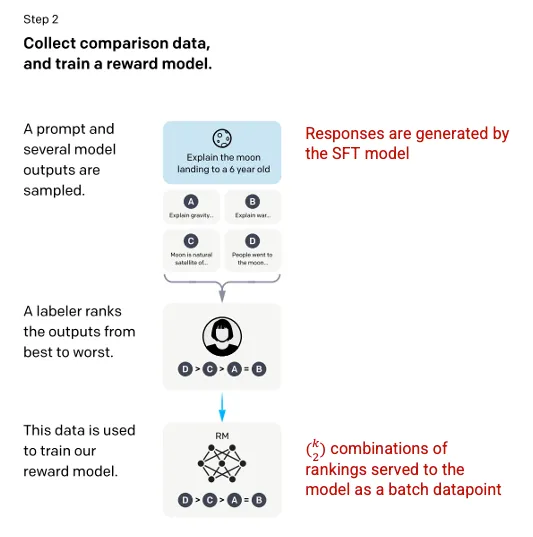
第二步:奖励模型
在第一步中训练 SFT 模型后,该模型会对用户提示生成更一致的响应。下一步是训练奖励模型,模型的输入是一系列提示和响应,输出的是一个标量值,叫做奖励(reward)。奖励模型需要利用强化学习。在强化学习中,模型会学习生成输出,让奖励最大化(参见第三步)。
为训练奖励模型,打标签者会从 1 个输入中获取 4 到 9 个 SFT 模型的输出。他们需要对这些输出按照效果进行排名,创建的输出排名组合如下:

响应排名组合示例
把模型的每个组合作为单独的数据点,会导致过度拟合(无法泛化到未见过的数据上)。为解决这个问题,该模型把每组排名作为单个批次处理数据点来建立。
图片(左)插入自训练语言模型以遵循人类反馈的指令 OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf
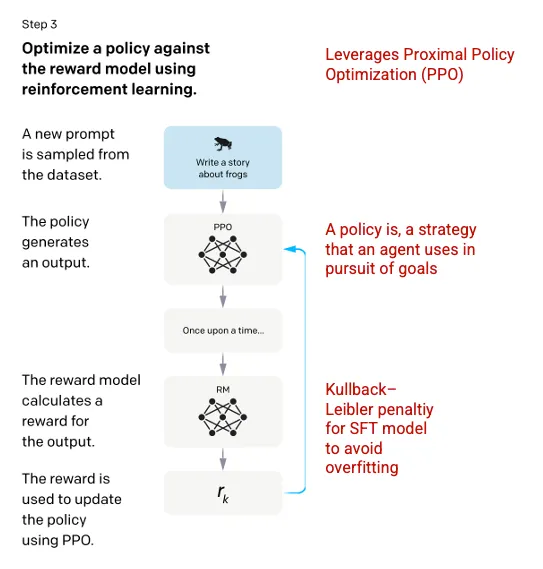
第三步:强化学习模型
最后,模型会收到一个随机提示并返回一个响应。该响应是模型在第二步中学到的“策略”生成的。策略意味着机器已经学会实现目标的方法,这里指奖励的最大化。基于在第二步形成的奖励模型,确定给定提示和响应对的标量奖励值。然后再将奖励反馈给模型,来改进策略。
2017 年,Schulman 等人引入了近端策略优化 (PPO),这种方法可以在模型生成响应时更新策略。PPO 方法结合了 SFT 模型中的基于标签的 Kullback-Leibler(KL)惩罚。KL 散度可以衡量两个概率分布之间的相似性,对距离过大的分布施加惩罚。这种情况下,使用 KL 惩罚可以减少响应与 SFT 模型在第一步中训练的输出之间的距离,避免过度优化奖励模型,导致响应过于偏离人类意图的数据集。通过引入 KL 惩罚,可以在训练过程中平衡模型的准确性和泛化能力。
图片(左)插入自训练语言模型以遵循人类反馈的指令 OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf
该过程的第二步和第三步可以重复进行,但在实践中还未被广泛采用。
ChatGPT 的屏幕截图
模型评估
评估模型时,会使用一组模型从未见过的数据集作为测试集。使用测试集进行一系列的评估,以确定该模型是否比其前身 GPT-3 有更好的适应性。
有用性:模型推断和遵循用户指令的能力。在 85 ± 3% 的时间里,相较于 GPT-3 的输出,打标签者更喜欢 InstructGPT 的输出。
真实性:模型产生“幻觉”的倾向。用 TruthfulQA 数据集进行评估时,PPO 模型产生的输出的真实性和信息性有小幅增加。
无害性:避免生成不当、贬损和诋毁内容的能力。研究人员利用 RealToxicityPrompts 数据集测试了无害性。测试在下列三种条件下进行:
- 指示提供有礼貌的回应:有害反应显著减少。
- 指示提供回应,没有表示尊重的设定:有害性没有显著变化。
- 指示提供毒性/贬损性的回应:回应的有害性远高于 GPT-3 模型。
想了解更多关于 ChatGPT 和 InstructGPT 所用方法的信息,可参见 OpenAI 的原文《Training language models to follow instructions with human feedback》,2022 https://arxiv.org/pdf/2203.02155.pdf。
ChatGPT 截图
感谢大家的阅读!
原文作者:Molly Ruby
原文链接:https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286