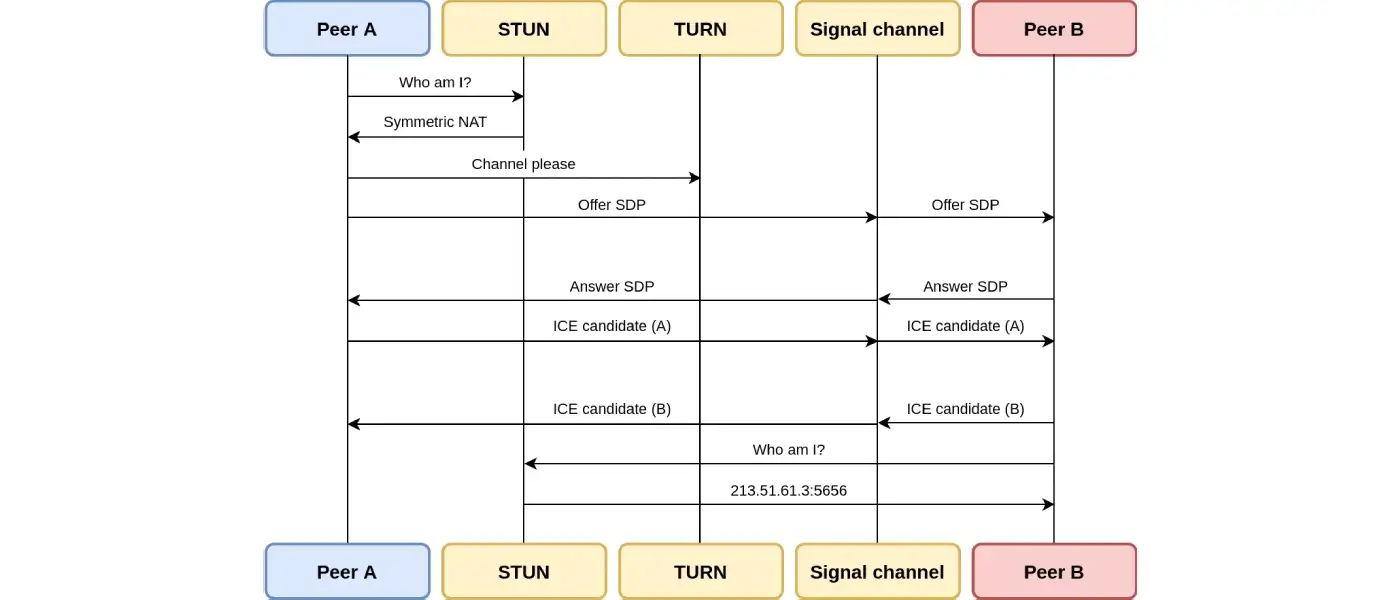
在软件领域,“back-pressure”指的是系统为“推回”下行力量采取的行动。也就是系统在受到胁迫,或在总调用模式表现出过多峰值,或过于突发时,单方面采取的一种防御性行动。
这种方法通常用于微服务基础设施。但在实时通信平台中没有被过多提及。其实它们对于处理负载峰值,同时将服务质量保持在合理的范围内也同样重要。在高峰期或突发期,服务质量可能会略有下降,但仍然可用。服务器是不应该停机的。
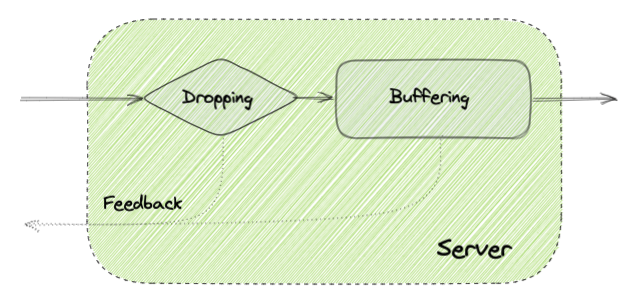
通常用来处理back-pressure,以免受那些不可持续流量模式影响的方法有这几种:缓冲、丢弃和控制发件人。
缓冲——消息可以排队处理。必要时用较低的速率处理,以此来限制高峰或高负荷的影响;
丢弃——当无法用足够快的速度处理信息甚至连接时,两者都可以放弃。但在客户端出现重试的情况下,这样做问题多多。因为该操作可能产生乘法效应使问题更加严重,所以必须谨慎使用该方法;
控制发送方——接收方可以向发送方反馈,限制其发送的流量,以暂时减少其对服务质量的影响。
信令平面和媒体平面通常用于构成RTC平台,下面来介绍上述方法应用于这两种平面的思路和影响。
信令平面
通常我们使用websocket连接来发送和接收与会话建立有关的信息,以及一些状态类型和消息传递。鉴于它是一种持久的TCP连接,所以我们其实已经免费获得了一些缓冲。作为操作系统实现的一部分,它可以解决一些流量高峰带来的问题。但除此之外,在连接和房间/会话级别上有一个更严格的缓冲会方便不少。这样可以避免在一个房间流量意外激增的情况下,单个房间让整个服务器的负担过重的情况。
丢弃信息在信令平面中并不常见。考虑到我们不希望丢失关键信息,万不得已不会选择丢弃操作。但在某些特定情况下,比如遥测信息或屏幕共享时发送光标位置,这不失为一种合理选择。
控制发送者可以明确进行(向客户端发送反馈信息,建议客户端通过增加一些批处理,或减少视频数量来发送更少量信息),也可以从缓冲区以较慢速度读取隐秘进行,这样客户端的相应缓冲区也会被填满。
媒体平面
当你运行媒体服务器时,会有一些默认的缓冲区存在,它们属于操作系统套接字实现的一部分。这些缓冲区的大小供你随意调整,帮你灵活处理峰值,用延迟换取丢包。传统用例中,你可能不会扩大缓冲区;但那些高比特率用例中,关键帧可能真的很大(例如类似Stadia的那些用例),可能会需要扩大缓冲区。这些缓冲区是处理小型峰值的第一道防线。但也不能滥用它们,因为缓冲区会增加媒体数据包的延迟和抖动。
丢弃信息也不失为一种选择。但一旦已经读取了这些信息,可节省的资源就变少了,因为会触发重传(至少在视频方面是这样)。所以与其丢弃数据包,不如禁用特定视频层的转发以减少数据包数量;或者在音频里启用动态dtx(即不连续传输)或增加ptime。
控制发送者应该是媒体计划中最常见的技术。有两种方法:一是在需要时配置较低的发送比特率(例如使用RTCP REMB消息)来明确控制发送者,二是隐秘地进行控制。在第二种情况中,如果媒体服务器开始过载,数据包的处理时间就不好预测了,这就会引入一些抖动。抖动是一种拥堵的信号,所以带宽估计也会降低。这在大多数现有RTC解决方案中是自动发生的。解决方案包括基于数据包延迟变化的带宽估计算法,例如WebRTC用例。
以上是我总结的用于信令和媒体服务器的一些技术方法。欢迎大家讨论。
文章地址:http://www.rtcbits.com/2022/01/back-pressure-in-rtc-services.html
原文作者:Gustavo Garcia