听觉超能力
想象一下,当你走进一个拥挤嘈杂的自助餐厅,并将所听到的各个说话者的噪音“分离”,这就是音频源分离的问题:将输入的混合音视频信号分解为它最初的来源。
声源分离,也被称为鸡尾酒派对问题,由于它的实用性:识别歌曲主唱、帮助聋人倾听、隔离逆风骑自行车时打电话的噪音等。因此,它是音频中最重要的问题之一。
我们提出了一种利用深度学习来解决这个问题的方法。
我们的数据
在解决这个问题时,我们使用了 UrbanNoise8K 和 LibriSpeech 数据集。UrbanNoise 数据集为我们提供了各种背景噪音,而 LibriSpeech 数据集为我们提供了在没有背景噪音的情况下阅读书籍的人们。我们自己发出声音以进行音调分离。
我们采用的方法
在对该主题进行初步研究后,我们决定使用频谱图代替原始波形来处理音视频。虽然Lyrebird’s MelGAN和OpenAI 的全新 Jukebox 在生成原始音频波形方面取得了成功,但我们项目的时间框架和神经网络的深度不允许我们与原始音频进行交互,因为它十分复杂。使用频谱图(原始 STFT 输出),我们不会丢失有关音频波形的信息,并且可以以非常小的损失重新创建它。
为了创新,我们决定尝试各种损失函数和训练架构,具体如下所述。
模型
我们为了这个实验尝试了许多不同的模型,从普通的卷积神经网络到密集层,但最终我们决定使用具有如下所述的U-Net 风格架构的模型A与模型B。
U-Net 架构兴起于图像分割,但后来也被用于频谱图分析。下图总结了架构,它涉及下采样层,该采样层能将图像的高度和宽度缩小到一个点,然后U-Net使用某种方式对图像进行上采样。在相应的上采样和下采样层之间具有相同形状的层之间添加残差(跳过)连接。
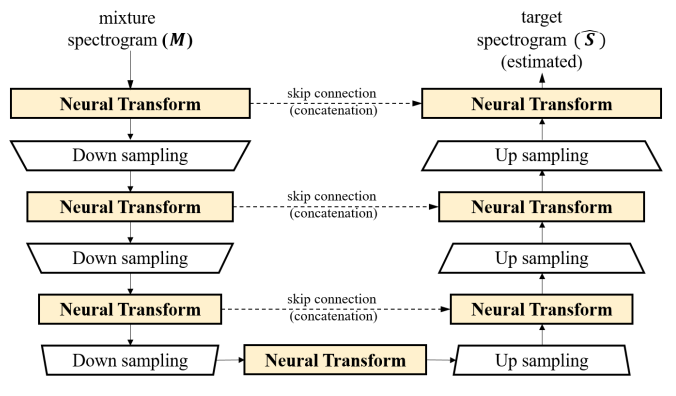
适用于音频的 U-Net 模型 从这里检索
我们根据以上引用的 Choi 等人的论文,在PyTorch 中从头提取了模型 A。这个想法与 U-Net 使用跳过连接的下采样和上采样方面非常相似。神经变换层仅更改图像中的通道数,而下采样/上采样层将图像的高度和宽度更改为 2 倍(简单卷积)。神经变换层和下采样层的数量从 7 到 17 不等。
每个神经变换层都是一个由 4 个 Batch-Norm、ReLU 和卷积操作组成的密集块,下文会提到。密集块是每个较小的块接收先前所有块的输出作为输入,本质上将通道添加到“全局状态”这个变量上,具体如图:
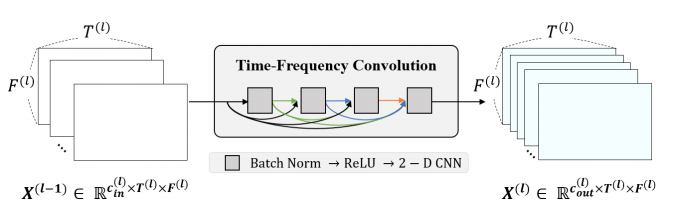
神经变换层图,从这篇论文中检索
模型 B 是模型 A 较小的版本,没有批处理规范层。这在下文引用的 Belz 博客文章中得到了验证。
模型A和模型B的输入是混合信号的频谱图。对于模型A来说,其输出值为预测语音的频谱图,目标值为目标个体语音的频谱图。与模型A 不同的是,模型B的输出值不是预测语音的频谱图,而是预测噪音的频谱图,目标值是目标噪声的频谱图。模型 B 中的语音是通过从输入混合信号中减去预测的噪声信号来预测的。
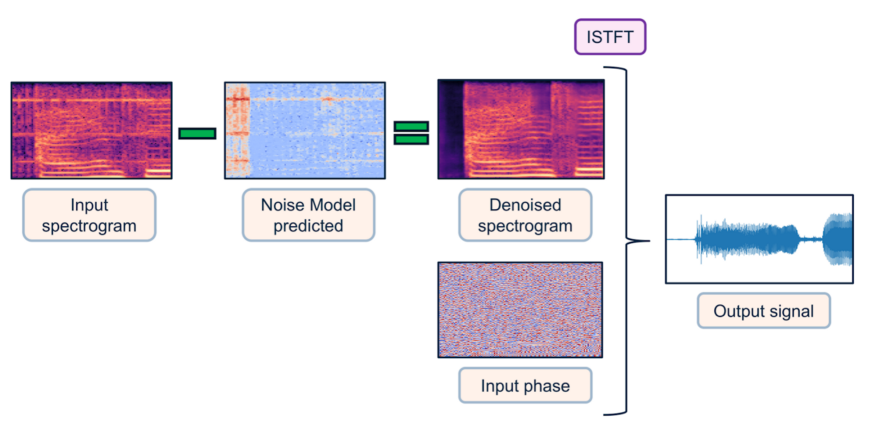
幅度频谱图描述 资料来源:Vincent Belz 来自Medium。
我们使用了两种类型的频谱图。一种是简单的 STFT 输出,它产生复值频谱图,代表实部和虚部的双通道图像。另一种类型只涉及将 STFT 的幅度作为单通道图像馈送,并在最后接收幅度频谱图。用于重建的短语只是初始 STFT 阶段(相位不变),如上图所示。
损失函数
损失函数是优化中最重要的部分之一,因为它决定了要缩小的表面。我们测试了以下损失函数,并使用了它们的线性组合与加权。
为了理解损失函数,让我们定义了一些变量:V 是语音频谱图信号,N 是噪声频谱图信号,M 是作为神经网络输入的混合音频信号。
M = V + N
V* 是生成器看到M后给出的预估语音。
M → 生成器 → V*
目标是让预估的声音尽可能接近真实的声音。
目标: V* = V
V、V 上的 MSELoss*
V、V 上的 MSELoss*
输出和目标之间的常规元素 MSELoss 是损失函数中的主要术语之一。这是一种被广泛使用的鲁棒损失,但它没有考虑到局部的的特征。
V、V *** 上的** 噪声加权 MSELoss
输出和目标之间的常规元素级 MSELoss,但具有基于该点的真实噪声强度的额外元素级加权。我们希望这将有助于专门消除噪音而不是重建声音(这相对容易做到)。
N, N 上的 Huber 损失*
Huber Loss 本质上是 MSELoss 和 MAELoss 的分段函数,在低误差值时,它的作用类似于 MSE,但经过某个阈值后,它变成了 MAE。这对异常值的惩罚少于 MSE,但在低损失值下具有相似的 MSE 属性。我们认为这有助于减小输出和目标之间的误差。
V、V 上的结构相似性 (SSIM) 损失*
与 MSELoss 不同,SSIM 损失最初是通过局部性来比较两个图像的结构相似性的。这个想法是 MSELoss 对两个非常相似的图像中的轻微偏移并不明显。该术语可以捕获两个频谱图的整体结构,并查看它们是否相同。
源投影损失
我们自己提出这种损失的想法与噪声加权 MSELoss 相同:专门去除噪声。与其在频谱图空间中工作,我们试图在频谱图的像素值上运行 MSELoss,如果有一个更简单的空间可以工作呢?基本的想法是你可以将所有频谱图视为大向量,通过投射到真实的声音和真实的噪声向量上,再加上一些正交的噪声假象来分解预估的声音向量。
分解: V* = a V + b N + R
现在的目标变为分别减小A、B、R为1、0、 0。
目标: V* = V → V* = 1 V + 0 N + 0
为了达到目标,我们可以在 a、 b,、 R 上运行 MSELoss为 1、0、 0 。
该损失函数直接测量与真实语音和部分真实噪声的关系。
但是,在实践中应用此方法时是会出现问题的。大部分损失来自最小化 R 噪声误差的幅度,而不是减少对噪声的投影。如果该项权重较小,则会出现 R 增长过多并将不需要的噪声伪影引入结果的问题,从而使这种损失弊大于利。
优化器
除非另有说明,否则到处都会使用学习率为 0.001 的 Adam 优化器。在源投影实验中,改用 SGD,因为它在输出中创建了较少的 R 向量伪影(采用了从 V + N 到 V 的更直接的线路径)。
音调分离
从一开始,我们决定简单地分离覆盖有恒定音调的声音。我们对模型的输入是一个人说话,在背景中播放声音,模型试图将声音与声音分开,只返回声音。运行模型 A,我们得到了非常好的结果,具体如下所示。
输入:
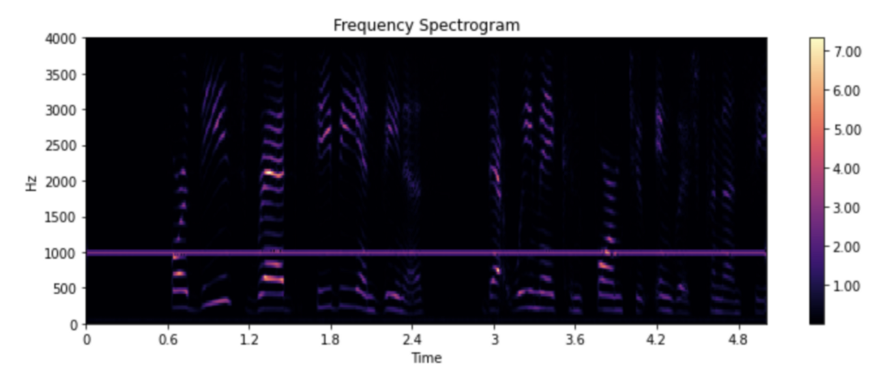
输出:

训练损失图:
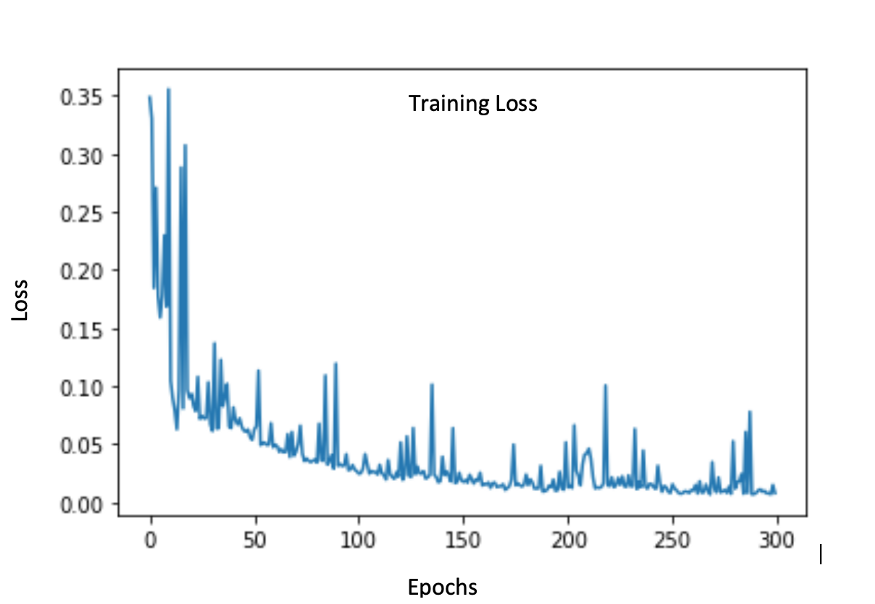
空调噪音分离
作为更高级的挑战,我们决定分离出覆盖有空调噪音的声音。我们对模型的输入是一个人在背景中嗡嗡作响有交流噪声的环境中说话,该模型试图分离交流噪声并只返回说话人的声音。运行模型 A,我们得到的结果没有达到标准,具体如下所示。
训练损失图:
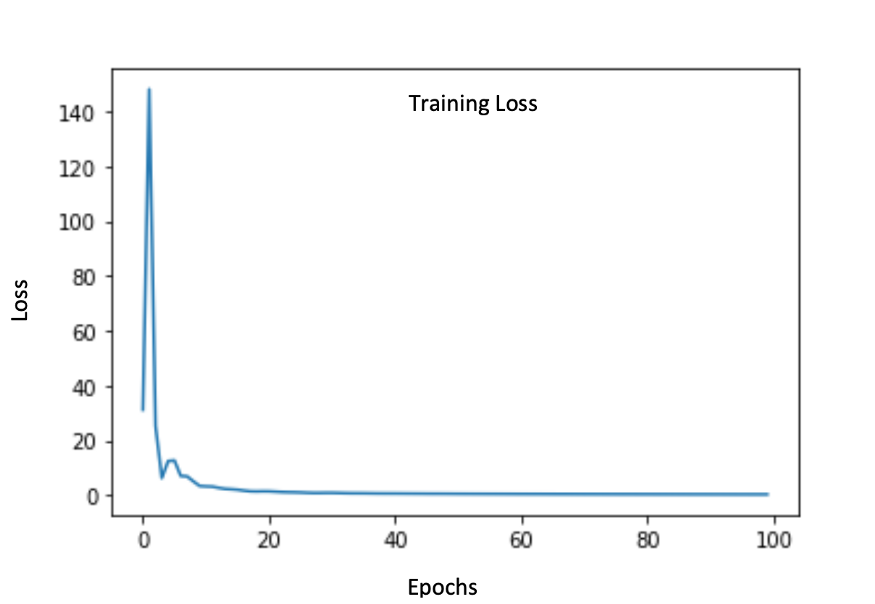
输入音频:
https://drive.google.com/open?id=1_7q0LLQ52WFUCDTiWze0f2olRCu-2rLC
输出音频:
https://drive.google.com/open?
使用 GAN 方法进行空调噪声分离
为了改进之前的结果,我们决定适应 GAN 方法。众所周知,GAN 很难训练并且可能不稳定。考虑到这一点,我们决定预先对生成器和判别器进行预训练,实质上是在训练过程中为它们提供“先机”。我们希望这会增加 GAN 的训练稳定性和收敛性。
由于我们已经有了一个经过训练的生成器,我们预先训练了一个鉴别器网络来区分真实的声音和来自生成器的预估声音。这是鉴别器的先验训练损失图:
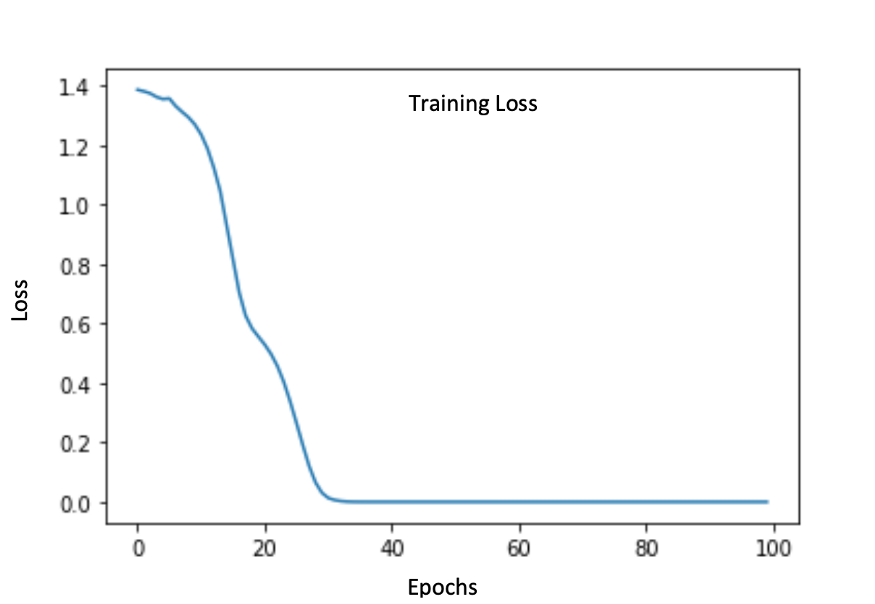
预训练后,我们在经典的对抗性设置中设置生成器和鉴别器并进行进一步训练。生成器损失是先前损失项以及鉴别器的新对抗性损失的组合。
这是生成器的训练损失:
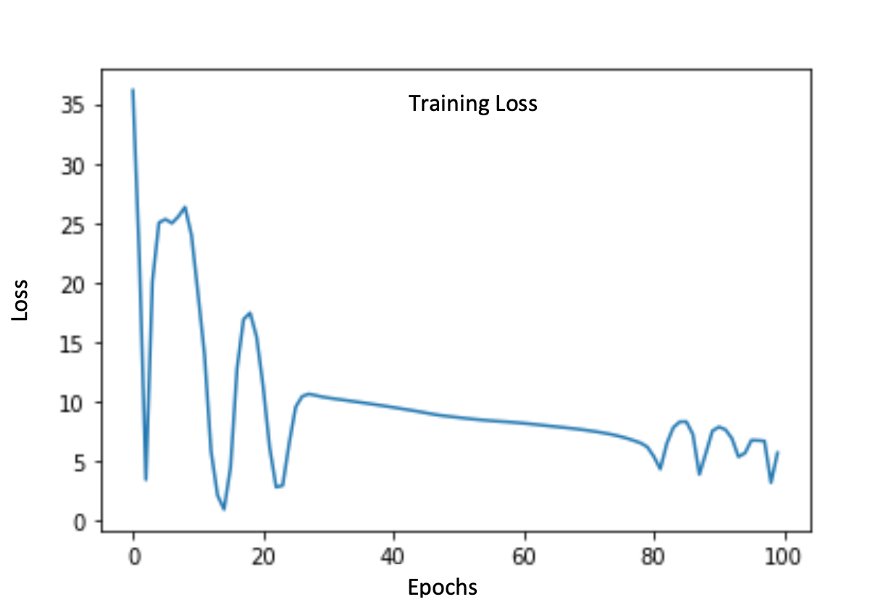
这是鉴别器的训练损失:
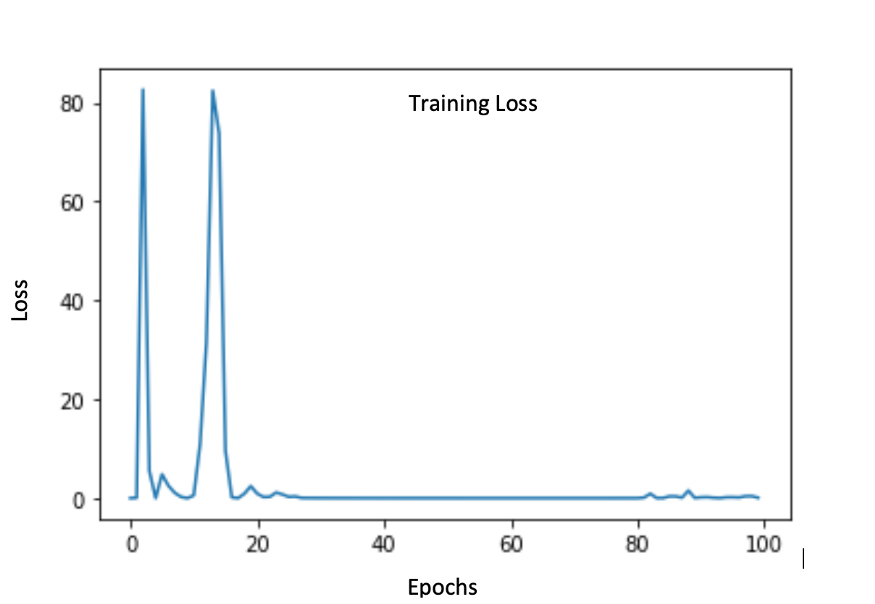
以下是我们在所有训练后取得的结果:
输入音频:
https://drive.google.com/open?
输出音频:
https://drive.google.com/open?
虽然结果听起来不太理想,但我们得出结论,这是因为我们的生成器不够深。为此,我们总共使用了 7 个神经变换层,当使用 GPU 进行训练时,可以很容易地将其增加到 17 个或更高。
狗吠分离
在我们的一项实验中,我们仅在嘈杂的语音上训练模型 B,而对于噪声,我们从噪声数据集中提取了不同的狗吠声。该模型使用 5000 条嘈杂的语音进行了 10 次训练。为了便于训练模型,每个嘈杂的语音音视频保持 1 秒的长度。
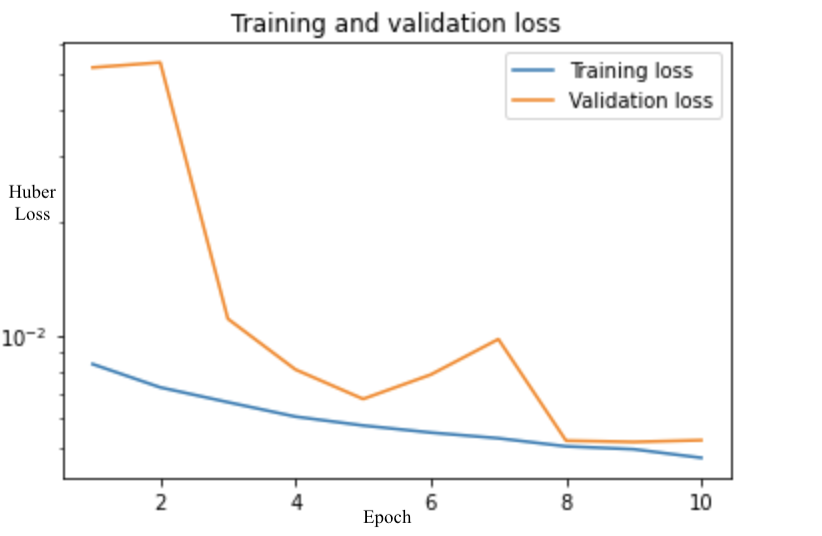
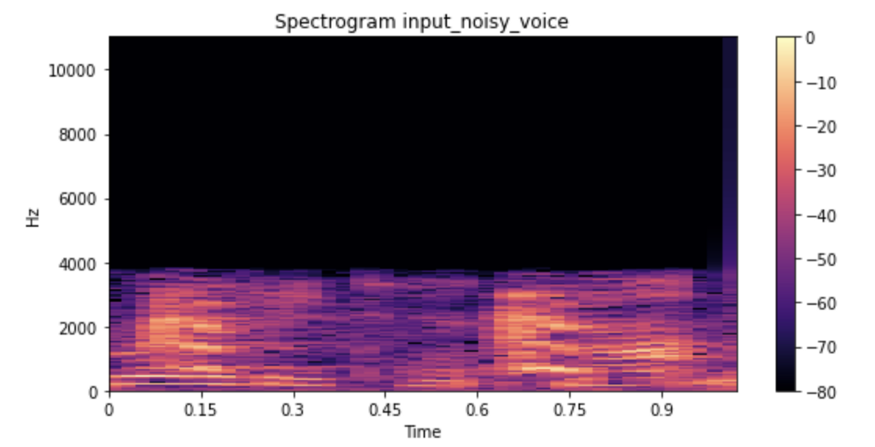
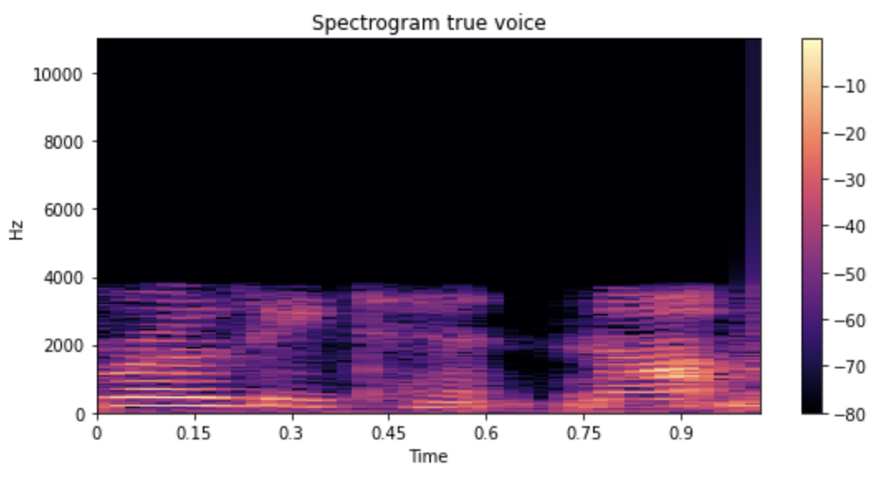
在训练模型后,我们使用该模型来预测干净的语音。下面我们分别展示了输入嘈杂语音、目标清晰语音和预测语音的频谱图和音视频剪辑。
输入:
https://drive.google.com/open?id=1-b27xEeqiWwDXFlwCM-igicFma_Gfy9U
输出:
https://drive.google.com/open?id=1hxZGgl5BA9WDZz8VaEi56EqjqsnO7Olh
总体而言,该模型在训练数据和验证数据上都表现良好。预测的 80 毫秒纯语音音频剪辑听起来非常像真实的声音。
网站
这是我们网站的链接:https : //audio-separation.herokuapp.com/
简而言之,我们的网站接受任意长度的嘈杂音频输入,通过我们的模型提供它的切片并将它们组合在一起,返回纯声音版本。用户可以选择将声源添加到他们的输入中以测试模型是否有效。我们使用 React.js 开发前端,使用 Python Flask 开发后端。我们面临的主要挑战是后端处理前端发送的任意长度的音视频文件。此外,我们不得不面对 Heroku 云实例内存不足的问题,因为 Tensorflow 和 PyTorch 占用了大量空间。为了解决这个问题,我们切换到 AWS,它可以选择更大的存储空间。一旦我们解决了安装正确包和有足够内存的后勤问题,

结论
我们在该项目中完成了大量工作。我们的模型A在音调分离方面表现非常好,但在去除复杂的空调噪音时由于其浅度而存在缺陷。我们的模型 B 比我们的模型 A 小,在狗吠声方面表现良好。模型 B 的变化是我们预测了噪声而不是更复杂的声音,并从我们的输入声音中去除了预测的噪声。另一方面,在模型 A 中,我们使用了更直接的方法,因为我们尝试直接预测无噪声语音。在这两种模型中,我们自己的 U-net 架构版本都发挥了关键作用。
我们的主要方法是创建一个鉴别器网络和生成器,独立地对它们进行预训练,然后过渡到像 GAN 这样的对抗式训练。对于这种方法,我们使用投影损失通过将估计噪声与残差项一起投影到真实语音和真实噪声中来直接去除噪声。然后使用 MSE,我们能够尝试训练我们的模型以忽略实际噪声和残差项组件。虽然这种方法无法通过空调噪音产生我们希望的结果,但我们相信,如果我们用更强的计算能力和更深的网络来训练它,它就会成功。
未来的工作
这个项目还有很多工作要做。从尝试鸡尾酒派对问题的完整解决方案到通用噪音分离器,我们仍然希望看到更多的成果。我们在这个项目中采取的下一步将首先尝试创建可以学习分离各种噪音的模型。虽然我们已经能够创建可以处理个人噪音(例如狗叫声)的模型,但更复杂的噪音(例如警笛)是我们无法实现的。在此之后,我们希望继续结合这些单独的模型来创建一个单一的更通用的模型,可以从语音中去除任何类型的噪音。在这里,我们甚至可以更进一步,尝试识别我们正在消除的噪音。最后,我们的最终目标是解决多个扬声器,特别是使用 GAN。这将是一个更具挑战性的问题,因为我们必须从噪声中识别语音并尝试将每个单独的声音与其他声音分开。
原文作者 Akarsh Kumar
原文链接https://towardsdatascience.com/audio-source-separation-with-deep-learning-e7250e8926f7