去年,我们发布了Scribe,这是一种用于金融音频的端到端神经语音到文本的 (STT) 系统。在培训期间,Scribe 利用了大量专业转录公司收益电话的内部语料库。生成的转录单根据出版质量的风格指南完全格式化,使其适合以端到端的方式训练 STT 模型。在创建 Scribe 时,我们广泛利用了学术文献中的最新研究。为了回馈研究社区,我们现在发布 SPGISpeech,这是一个 5,000 小时的 STT 数据集,可免费供学术使用。你可以下载 SPGISpeech并在我们的预印本中进行详细了解,该预印本由 NVIDIA、卡内基梅隆大学和约翰霍普金斯大学的合作者共同撰写。
SPGISpeech 样本材料与现代商业一样广泛。同许多其他 STT 数据集相比,SPGISpeech 捕获了各种现实世界的话语特征。在我们进行深度讨论之前,这里有一些 SPGISpeech 的示例。
SPGISpeech 提到了当代公众人物和组织:
转录:“想想奥巴马总统祝贺埃隆·马斯克历史性的 SPACEX 登陆,或者全世界为传奇艺术家普林斯的遗产而庆祝。”
它包含从时事中提取的新颖词汇:
转录:“但我们仍在通过提醒客户冠状病毒声明的重要性来积极取代该产品,而他们的产品则没有这项功能。”
它甚至包含公共语料库中经常省略的随意话语,但对于理解专业人士如何讨论其领域的问题至关重要:
转录:“你不会完全被困在一项活动中,就像当狗屎击中风扇时HMT一样。所以我认为这是一件好事。”
为什么是另一个 STT 语料库?
英语金融音频有许多不同寻常的特点,这使得它给 STT 带来了独特的挑战性。例如,它包含诸如“EBITDA”之类的金融术语以及以非标准方式使用的标准英语单词,例如“指导”作为“预计收益”的同义词。对于 STT 系统,甚至是非专业母语人士来说,这些都可能具有挑战性。SPGISpeech 包含许多此类示例,包括会计简写和产品名称以及社会、政治和经济组织的首字母缩略词。
然而,行话并不是唯一的挑战。金融音频通常包含多种话语模式,例如准备好的演讲和问答环节。这些模式的声学特性可能有所不同:例如,由于自发性,问答往往会更多的发言者参与、更多的谈话话题和时不时被打断,以及一些粗鲁的发言。对于仅在一种模式上训练的模型来说,要很好地推广到另一种模式可能具有挑战性。SPGISpeech 包含的是先准备好的、有叙述的演讲以及公司官员和分析师之间的自发对话。
金融音频还包括各种本地和外国口音。从历史上看,商业 STT 模型需要对单个用户的语音进行训练才能获得良好的性能。这对于金融音频的机器转录是不可行的,因为源材料不仅包含许多不同人的声音,而且还包含不同的口音。另外,必须记住的是,虽然演讲者通常英语很流利 ,但英语并不一定是他们的母语,因此,他们可能偶尔会犯一些小错误。当这些错误不会对演讲的含义产生实质性影响时,最佳做法是在转录中修复它们。SPGISpeech 自然地对这种语言多样性进行了采样:虽然北美口音占 SPGISpeech 来源材料的绝大部分,但也有来自地球上每个可居住大陆的演讲者。将轻微的语法错误与正确的同源转录配对对于构建能够通过解释性慈善进行转录的 STT 系统至关重要。
抄录:“下半年,毛利率没有这么大的提升。” SPGISpeech 修复了一个常见的小错误(在“年份”之前遗漏了定冠词)。
最后,大多数专业英语文本都是用标准拼写法 编写的,这是一套标点符号、大写和某些非标准单词的非规范化的约定,例如“$1.23”代表“A DOLLAR TWENTY THREE”。在转录自发语音时,必须有处理停顿、不流畅和自我纠正等自然特征的惯例。标准正字法使文本要表达的含义变得不那么模糊,更易于读者阅读。由于 SPGISpeech 是从约 100 页的样式指南在多阶段过程中专业转录的呼叫语料库中提取,它自然受益于转录过程中对提供适当正字法任务的特别关注。
端到端 STT 任务
最后一节中的示例突出了金融音频的一些微妙之处。在各种情况下,SPGISpeech 都采用相同的方法:完全按照最终书面副本中应有的形式呈现转录内容。这种格式实现了一种新的 STT 方法:端到端转录。
从历史上看,大多数 STT 系统将转录分成几个步骤。首先,声学模型 将声学信号转换为简单的、无大小写的文本,字母表通常由 26 个字母、一个空格和一个句子结束标记组成。接着,各种后处理模型通过预测正确的大写、标点符号、非规范化等来清理输出。这确实是我们在 Scribe 的第一次迭代中采用的方法:
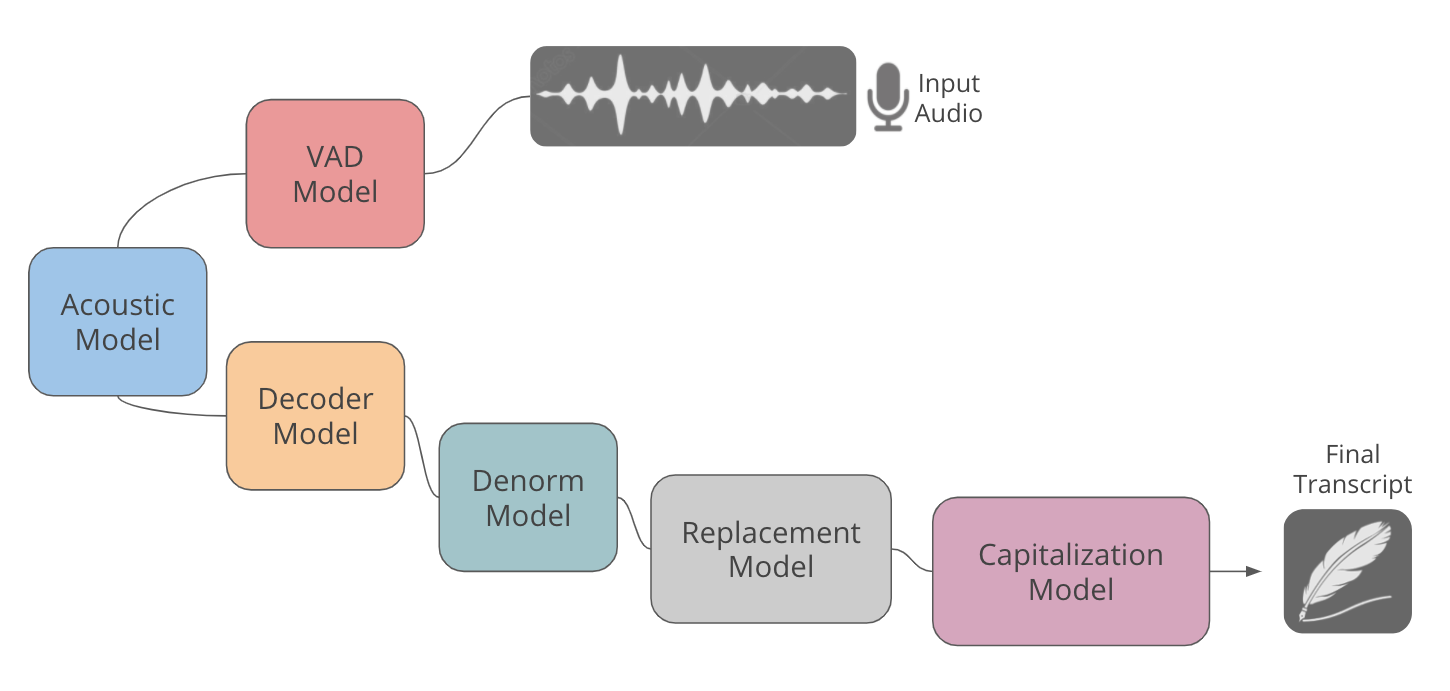
原始 Scribe Pipeline:音频在六个离散模型的过程中转换为文本,包括三个文本后处理模型。
这种方法具有一定的优势,例如模块化。更重要的是,当训练数据缺乏正字法时,这是唯一的选择。声学模型只能学习生成未格式化的转录本,其他模型必须在后期修复输出。
然而,这种方法有几点限制。首先,从实践的角度来看,维护链接的模型管道可能非常具有挑战性,因为对任何单个模型的更新都可能导致下游任何地方发生意外更改。然而,更重要的是,一个句子的正确拼写通常取决于它的含义。英语句子的含义通常部分是通过音频提示来传达的,这些提示可能会在转录中丢失并且以后无法从文本中推断出来。例如,短语“你将能够在今年支付更多股息”可以是声明或澄清请求——因此需要一个句号或问号——这取决于说话者的最终音调。
转录:“因此,你今年将能够支付更多股息?你在处理这个场景吗?” SPGISpeech 转录提供正确的句尾标点符号,允许声学模型从语调推断它们。
暂停、犹豫、不流畅和自我修正是声学信息对于正确转录至关重要的另一个领域。具体可看以下剪辑:
转录:“当你开始谈论 25% — 20% 到 35% 时,如果它们以明确的方式被强制执行,那么价格上涨是不可避免的,我认为这不太可能。” 短语“20-25% 至 30%”被转录为错报,随后进行更正,初始错报的百分比转录是基于更正的内容。
短语“当你开始谈论 25 20 到 35 % 时”在书面上非常难以解析。然而,音频包含一个澄清提示:“二十五”是一个误报,应该用更准确的范围“20% 到 35%”代替。修正后的是一个百分比范围,这一事实使我们能够得出结论,第一个数值实际上也是一个百分比:“25%”。
解析歧义经常出现,尤其是在语音中引用数字数据时。例如,根据重点和节奏,短语“AT ONE POINT ONE TWO PERCENT”可能更好地转录为“at 1.12%”或“at 1., 1–2%”。音频通常情况下足以恢复说话者的意图。
转录:“津贴为 1.12%。津贴绝对水平的增加是由于第二季度的贷款增长以及我们对津贴方法的一致应用。” 根据韵律线索,短语“ONE POINT ONE TWO PERCENT”被正确解释为“1.12%”(以及其他替代方案)。
上面的例子突出了从中间文本表示推断最终正字法的一些困难。另一种方法是简单地训练一个端到端模型,该模型直接从音频生成正字法文本。这样,模型就可以使用所有可用的信息来预测合适的拼写法。当然,这种方法需要大量完全格式化的训练数据。直到现在,很少有 STT 数据集提供完全正字法转录和可观的容量。
端到端训练使我们能够提高 Scribe 的准确性,同时从根本上简化其结构,如下所示:
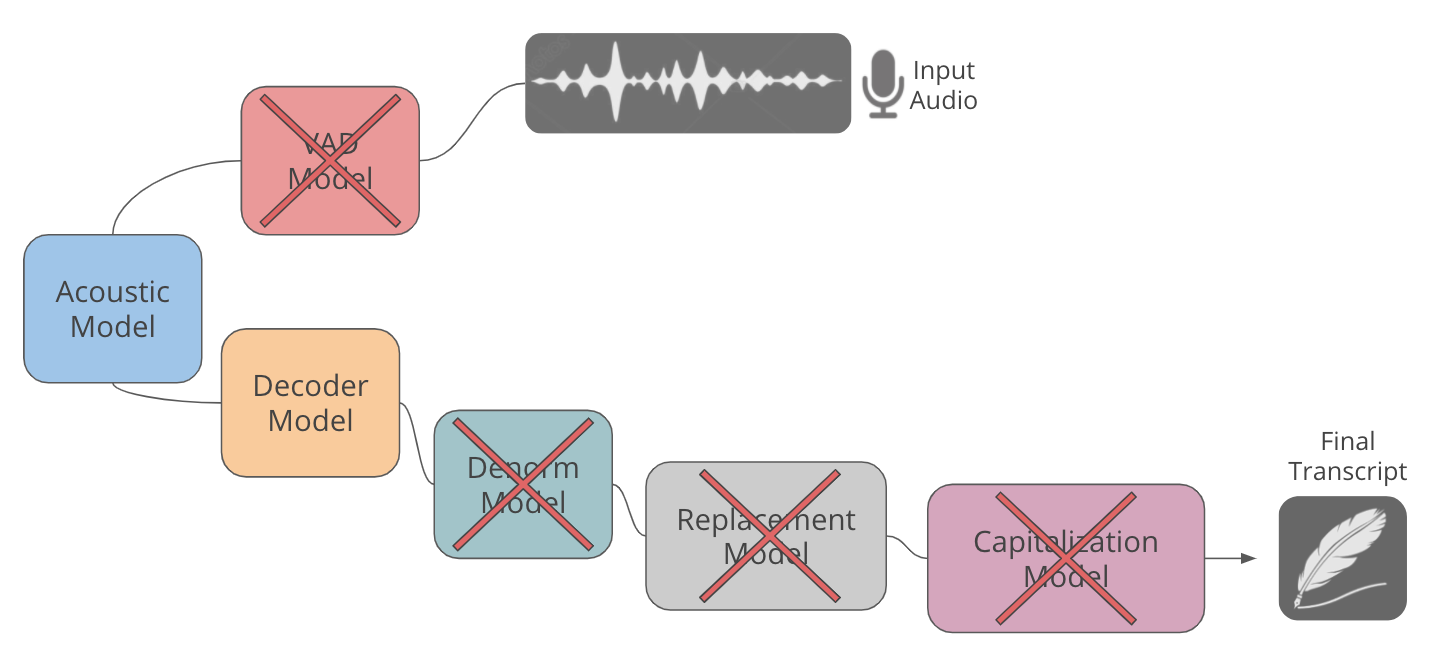
修订的 Scribe Pipeline:端到端训练使我们能够消除除声学和解码器模型之外的所有模型。特别是,反规范化、替换和大写后处理模型的职责现在都被吸收到声学和解码器模型中。
随着 SPGISpeech 的发布,我们希望加速对完全格式化的 STT 任务的研究,并鼓励更多的研究人员采用正字法转录作为评估模型性能的黄金标准。在我们看来,它是大多数转录类型最自然、最方便和最易读的目标,也是回馈研究社区的一种微小力量,他们的工作首先使 Scribe 成为可能。
如果你想将 SPGISpeech 用于学术用途,可以点击此处。你还可以在此处阅读我们的预印本。联系我们团队讨论商业或其他用途。
原文作者 Kensho Blog
原文链接 https://blog.kensho.com/spgispeech-5-000-hours-of-fully-formatted-financial-audio-for-speech-to-text-ac3d26ff842a