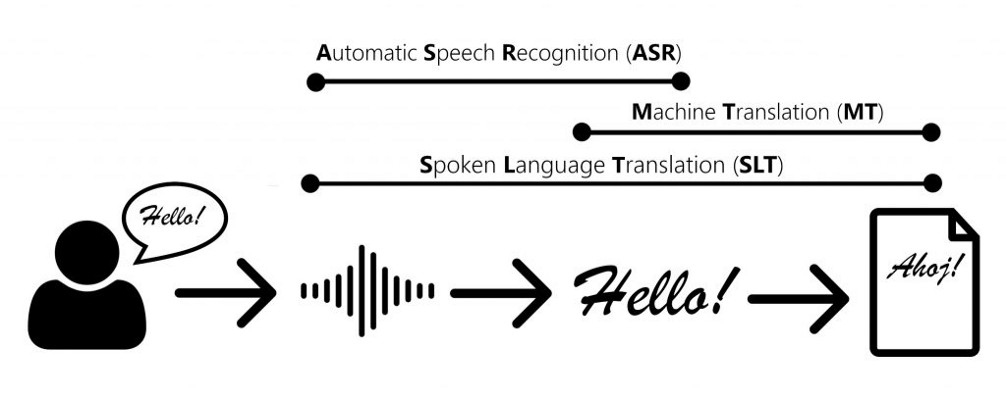
ASR 使机器能够接收、识别和理解人类的话语
人工语音识别(ASR)是一种机器学习模型,它能将语音翻译成文本,也能识别并理解人类语言。

图片由https://www.hindipanda.com/speech-recognition-technology/提供
总览
- 口语
- 应用
- 挑战
- 历史
- 模型
- HMM (隐马尔可夫模型)
口语
说!每个人都通过说话与其他人交流。我们用带有特定声波的声音交谈、彼此了解。在声波中,它不显示特定的单词。模型(计算机)如何理解我们?我们可以通过使用 CNN(卷积神经网络)来识别图像,因此我们使用 ASR(自动语音识别)或“语言模型”来识别甚至理解人类语言。

交流——图片来自https://medium.com/@raihamalik/effective-communication-5321d663ee5a
高科技和口头说明
我们通过键盘输入来访问技术或社交媒体,使用我们的“声音”来指导计算机或高科技设备,我们的日常生活将变得更加轻松、方便和直观。因此,人工智能在各种应用中得到广泛应用,并在众多设备和服务中得到改进和实现。
应用
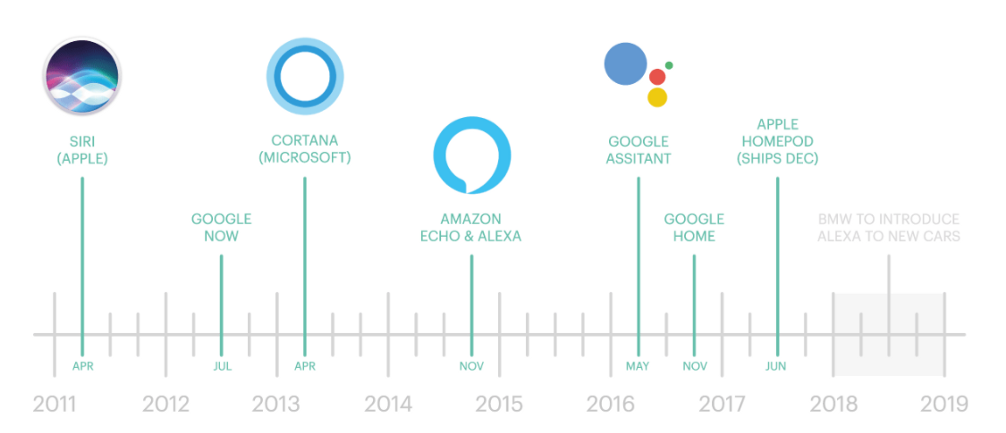
ASR在日常生活中有各种各样的应用,比如最流行的虚拟助手。
虚拟助手, 例如 Google Assistance 、 Siri 和 Amazon Alexa 。

虚拟助手

谷歌助手
语言学习

语言学习
机器人

机器人
家庭自动化

家庭自动化
医学转录

医学转录
挑战

-
麦克风距离
用户使用麦克风的距离不同,每个应用程序都需要自己的处理过程。
1.1 近场——官方录音和复制
1.2 中场——普通在线会议(演讲者坐在电脑前)
1.3 远场——大型研讨会,放置在大厅内的各种麦克风距离。 -
语音压缩
有损:通过删除数据来 减小 文件大小
无损:在不丢失细节的情况下进行压缩
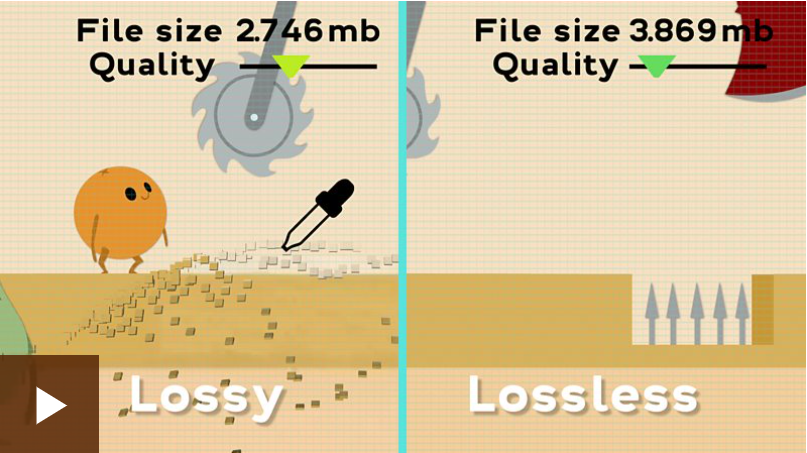
图片来自https://www.bbc.co.uk/bitesize/guides/zqyrq6f/revision/4
- 交互类型

历史
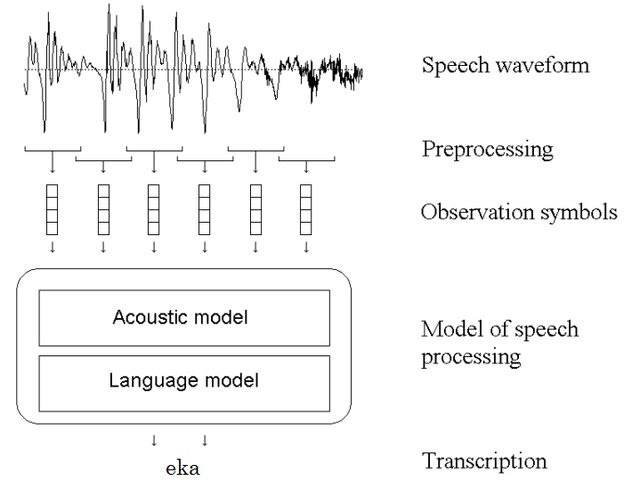
模型
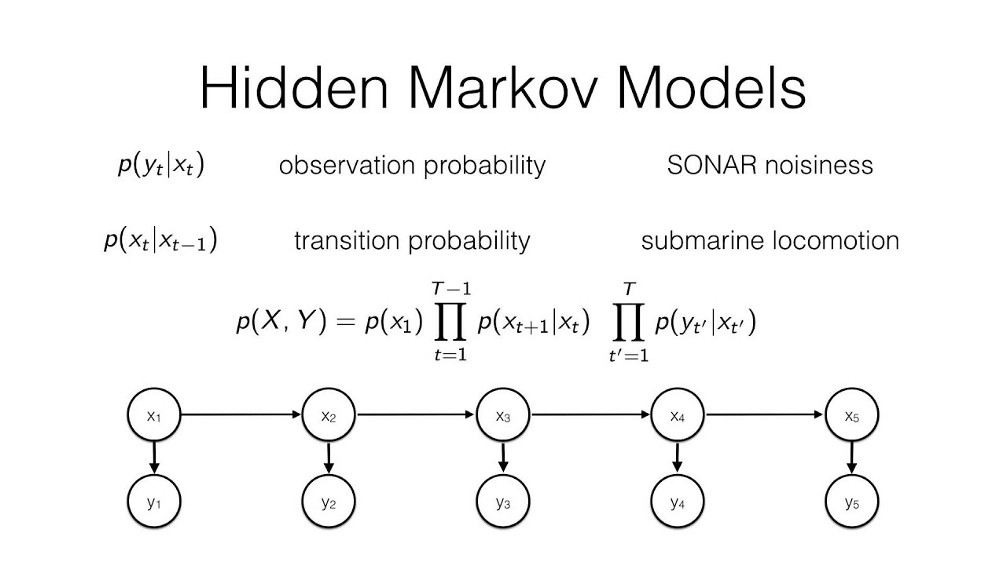
HMM(隐马尔可夫模型)
基于先前状态或条件的概率假设。

隐马尔可夫模型
隐马尔可夫模型是马尔可夫模型的一类,用于具有生成某些观察事件的隐状态的系统。这意味着有时,人工智能可以对世界进行一些测量,但无法获得世界的精确状态。在这些情况下,世界的状态被称为* 隐藏状态 ,人工智能可以访问的任何数据都是 观察 *。这里有几个例子:
对于探索未知领域的机器人,隐藏状态是它的定位,观察是机器人传感器记录的数据。
在语音识别中,隐藏状态是说的话,观察是音频波形。
在衡量用户在网站上的参与度时,隐藏状态是用户的参与度,观察是网站或应用程序分析。
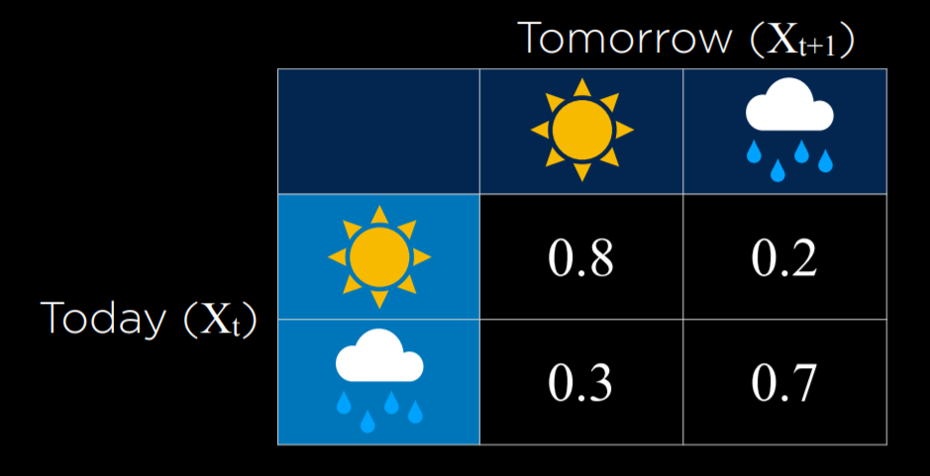
对于我们的讨论,我们将使用以下示例。我们的 AI 想要推断天气(隐藏状态),但它只能使用室内摄像头来记录有多少人随身携带雨伞。这是我们的* 传感器模型 (也称为 发射模型 *),表示这些概率:
代码由https://cs50.harvard.edu/ai/2020/weeks/2/ 提供
from pomegranate import *
# Observation model for each state
sun = DiscreteDistribution({
"umbrella": 0.2,
"no umbrella": 0.8
})
rain = DiscreteDistribution({
"umbrella": 0.9,
"no umbrella": 0.1
})
states = [sun, rain]
# Transition model
transitions = numpy.array(
[[0.8, 0.2], # Tomorrow's predictions if today = sun
[0.3, 0.7]] # Tomorrow's predictions if today = rain
)
# Starting probabilities
starts = numpy.array([0.5, 0.5])
# Create the model
model = HiddenMarkovModel.from_matrix(
transitions, states, starts,
state_names=["sun", "rain"]
)
model.bake()
原文作者 Prim
原文链接 https://medium.com/super-ai-engineer/artificial-speech-recognition-aa8388d1b7f3