


本文作者:声网 Agora 工程师 @elegenxi
在 RTC 2019 第五届实时互联网大会的编解码技术专场上,声网开源了自研抗丢包音频编解码器Agora SOLO。
这个开源项目兼容 WebRTC,可集成于多种场景下的实时音视频应用中,比如在线课堂、直播社交、游戏语音开黑、IoT 等。在分析它的特性之前,首先要讲一下它名字中的一个关键词,丢包。
丢包是什么?
尽管很多人开始使用 WebRTC 了,但是其中有不少人都对「丢包」的概念不是很熟悉。所以,首先我们要解释一下。由于 SOLO 是音频编解码器,我们接下来讲的场景,主要是指其中的实时音频部分。
我们现在的互联网生活中有各种各样的实时音视频互动场景,比如:
- 泛娱乐社交:直播连麦、跨直播间 PK、游戏语音开黑等
- 在线教育:一对一教学、双师课堂、大班课、在线音乐教室等
- 其它创新场景,包括 VR、机器人等
这些场景都需要通过网络进行实时传输。如果我们将互联网看作为高速公路,那么音频数据是一辆辆车。丢包就是有的车无法在有效时间内无法达到终点,甚至可能永远也到不了终点。假如我们的一百辆车里有五辆车没能到达终点,我们这次车队传输的“丢包率”就是5%。是的,互联网传输也一样,它并不是百分百可靠的,总有数据无法按时传输到目的地。
如果丢包率大,会造成什么后果呢?
如果丢包比较严重,微信电话、视频聊天或语音连麦的时候,你听到的对方的声音可能音质很差,甚至是断断续续的,或者干脆没有声音。而这种情况在任何网络下都可能出现。不论你是通过 Wi-Fi、4G 还是 5G,都可能因为进入地下车库、进入电梯、信号覆盖不良、网络带宽受限等原因,遇到这些实时音频体验问题。所以,这就需要抗丢包策略,来保障音频体验。
我们曾在一篇内容中详细讲过传统的抗丢包策略,在这里我们不赘述。然而,传统的抗丢包策略不是会浪费带宽,就是会影响音频质量,所以我们结合信源和信道编码的特点,利用充分包交换网络的特性,基于此,研发出了抗丢包音频编解码器——Agora SOLO(以下简称“SOLO”)。
SOLO 是什么?
SOLO 是由声网Agora自主研发的一款抗丢包音频编解码器。在
更重要的是,SOLO 编解码器兼容WebRTC。如果开发者正在基于 WebRTC 开发自己的应用,可将 SOLO 集成到其中。
要知道,WebRTC 默认使用的是 Opus 作为编解码器,而 Silk 与 Opus 有千丝万缕的联系,我们曾经在RTC 专栏的一篇投稿中讲过。而 SOLO 则是以 Silk 为基础,融合了带宽扩展(BWE)和多描述编码(MDC)等技术,使其能在较低复杂度下拥有弱网对抗能力。也就是说,在 SOLO 的帮助下, WebRTC 应用可以更好地应对不稳定的网络环境,对音频质量与体验带来有效的保障与提升。
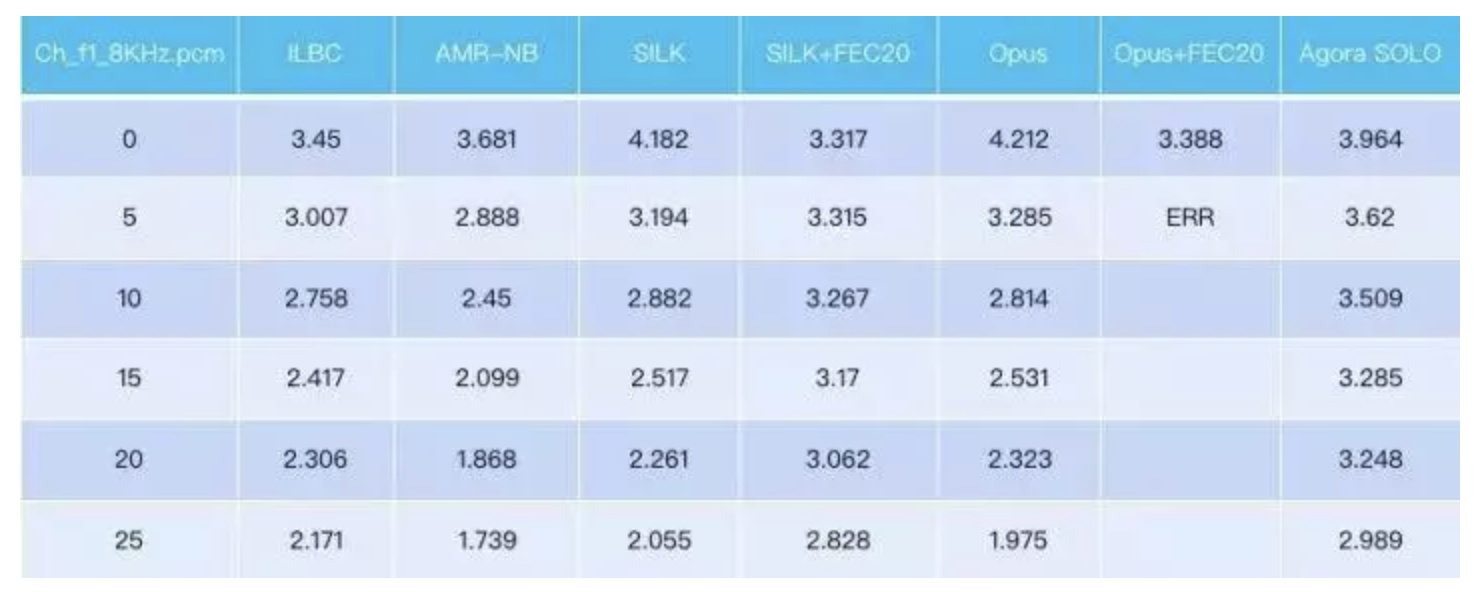
根据我们此前的测试(如下图),一个中文的女声序列在不同编解码器下的 MOS 分比较。第一列是不同的丢包率,后面各列是不同编解码器在不同丢包率下的分数。可以看到在丢包率25%时,SOLO 的 MOS 分比其它编解码器有所提高。当然,我们还在此前的内容中公开过更多跑分的细节。
利用 SOLO,可以不再关心网络丢包状态,因为它会默认发两个包。如果只收到一个就是有限失真,收到两个就是高质量的恢复。
下面,我们看一下 SOLO 编解码器的架构。
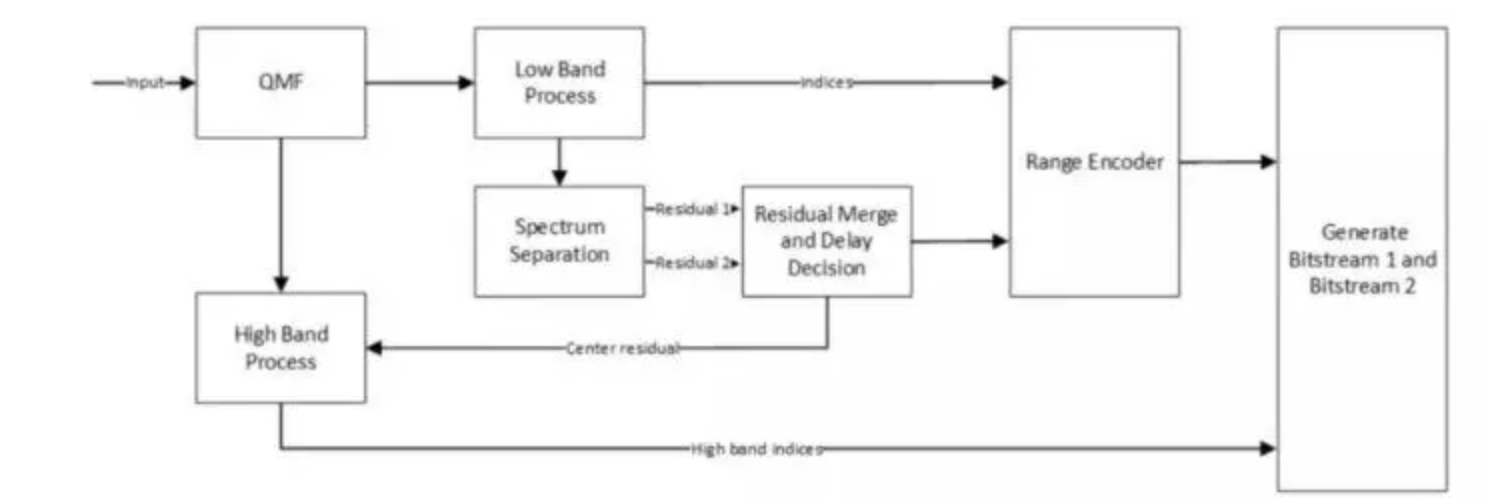
图 1. SOLO 编码器架构
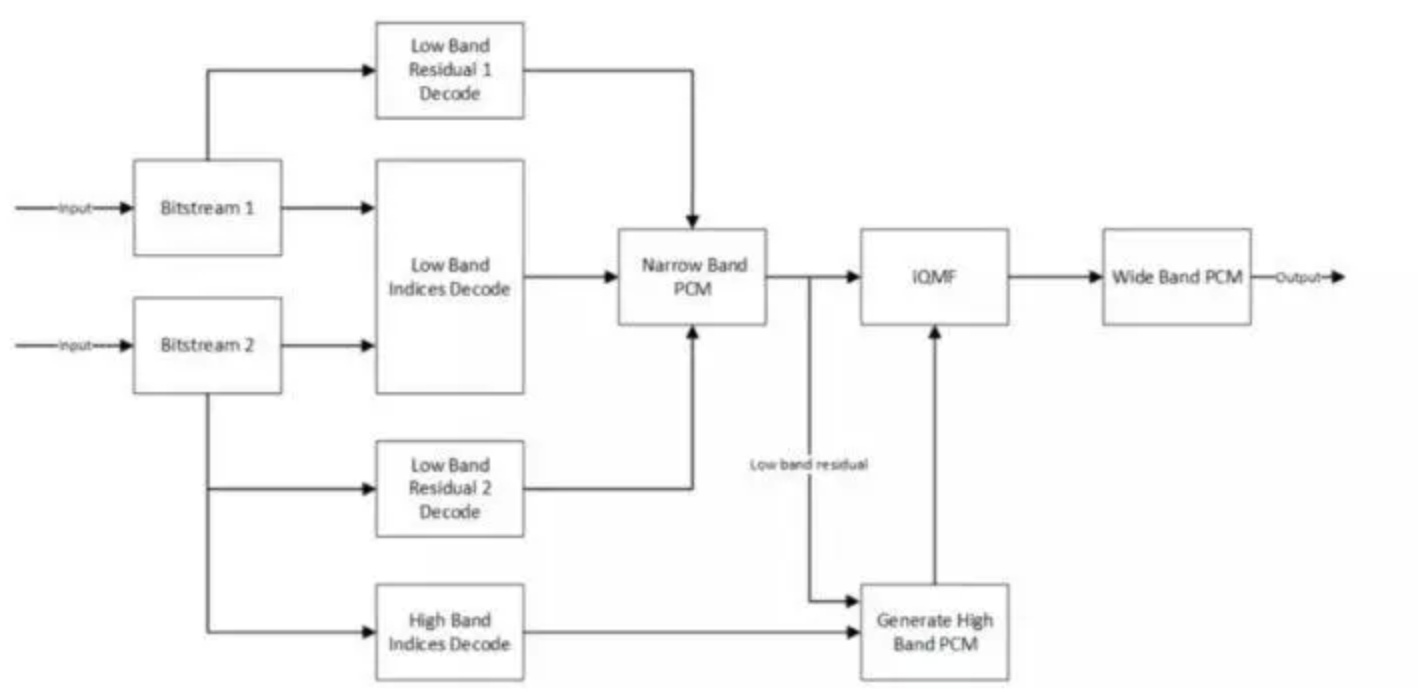
图 2. SOLO 解码器架构
SOLO的抗丢包策略与传统方法不同。从通信原理来说,信源编码是尽可能去追求高压缩比,去冗余。而信道编码是追求强纠错,靠加冗余来实现纠错。SOLO 就是把加冗余和减冗余结合起来,不重要的地方减冗余,重要的地方加冗余。在传输过程中,它会将一个包拆分为两个进行传输,如果对端收到其中一个,则解码恢复出一个有限失真的信号;如果对端收到两个包,则可解码恢复出一个高质量的信号。即 SOLO 不需要等待对当前网络丢包状态的统计,只需要直接把抗丢包做到编解码内部。好处有三点:1.可实现更低延时;2.可实现更高质量,当收到一个包时质量达到的普通编解码器水平,收到两个包达到高质量编解码水平;3. 可面向多人环境。
SOLO 关键技术
一、带宽扩展
SOLO 使用带宽扩展的主要原因是希望减少计算复杂度,在 Silk WB 模式中,16khz 的信号都会进入后续处理模块,而对于语音来说,8khz 以上的信息是非常少的,这部分信息进入到后续处理模块,会带来一定的计算资源浪费。MDC 因为要引入额外分析模块处理多条码流,又会引入额外的复杂度,这是 MDC 在近些年来落地不顺畅的重要原因之一。为了减少复杂度,我们在编码宽带信号前,将其分为 0-8k 的窄带信息和 8-16k 的高频信息。只有窄带信息会进入到后续正常分析、编码流程中,这样后续的计算量就减少了一半,同时得益于带宽扩展算法,整体质量不会有明显下降。高频信息部分,SOLO 使用独立的分析与编码模块,默认将高频信息压缩成 1.6kbps 的码流。这部分高频信息可以在解码器内结合低频信号恢复出高频信号。
二、结合 delay-decision 的 MDC
在 Silk 中,delay-decision 模块是一个滞后计算编码误差的模块,它可以从多个候选码流中选择误差最小的码流作为编码输出,一定程度上来说,它使得标量量化拥有了矢量量化的性能。SOLO 利用 delay-decision 模块,实现了多描述码流的分析与构建。SOLO 的MDC主要作用于滤波器输出的残差信号, SOLO 会根据当前信号状态,对残差信号做多增益控制:计算出 MD 增益 a(0<a<1),将 a 作用于奇数子帧,并将(1-a)作用于偶数子帧以产生两段互补的残差信号,这里记作 residual 1 和 residual 2。
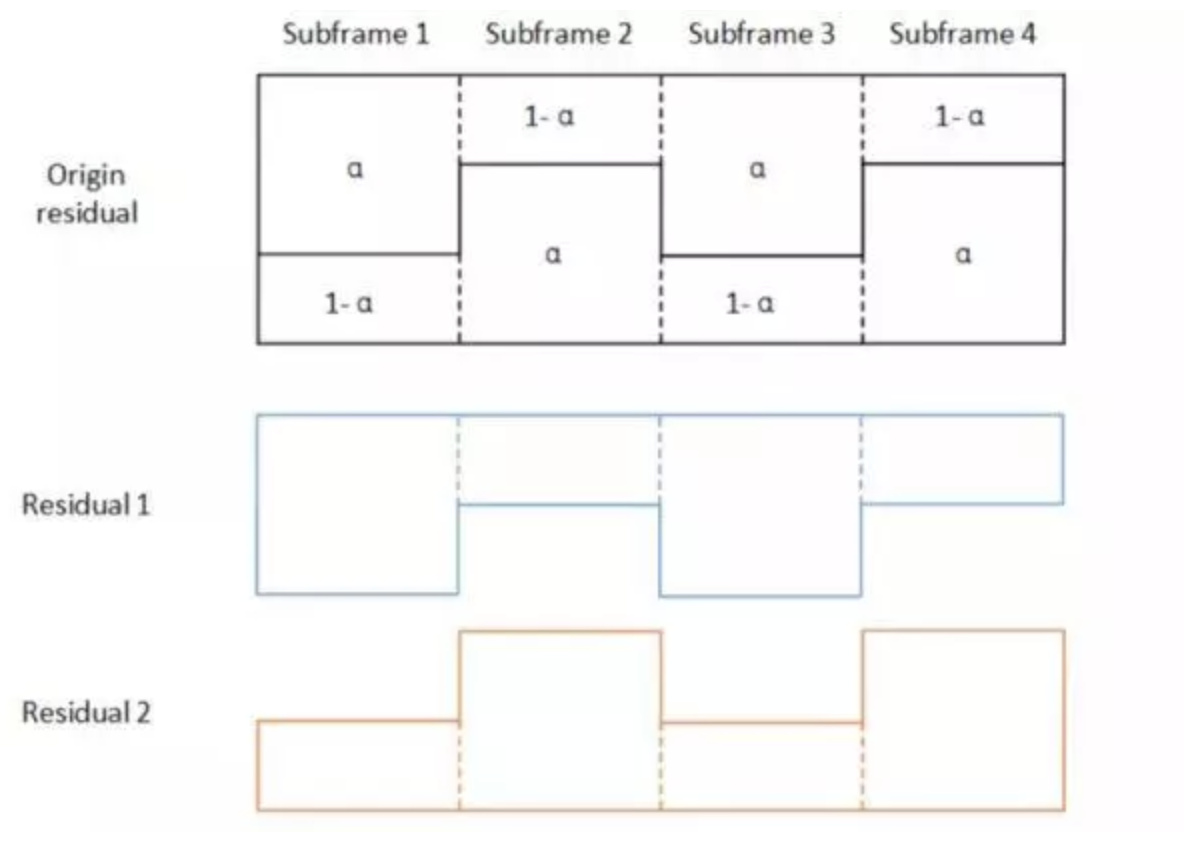
图 3. 多描述残差信号产生
随后,这两段残差信号会进入到新的 delay-decision 模块中,每个残差信号使用不同的抖动和量化方法,一共可以产生 8 种不同的备选状态,两两组合起来共有 64 种备选合成状态,新的 delay-decision 模块会对每个残差信号的独立误差和两个残差信号的合成误差进行加权求和,决定出最佳的两个残差信号进入到编码模块。
三、输出码流组包
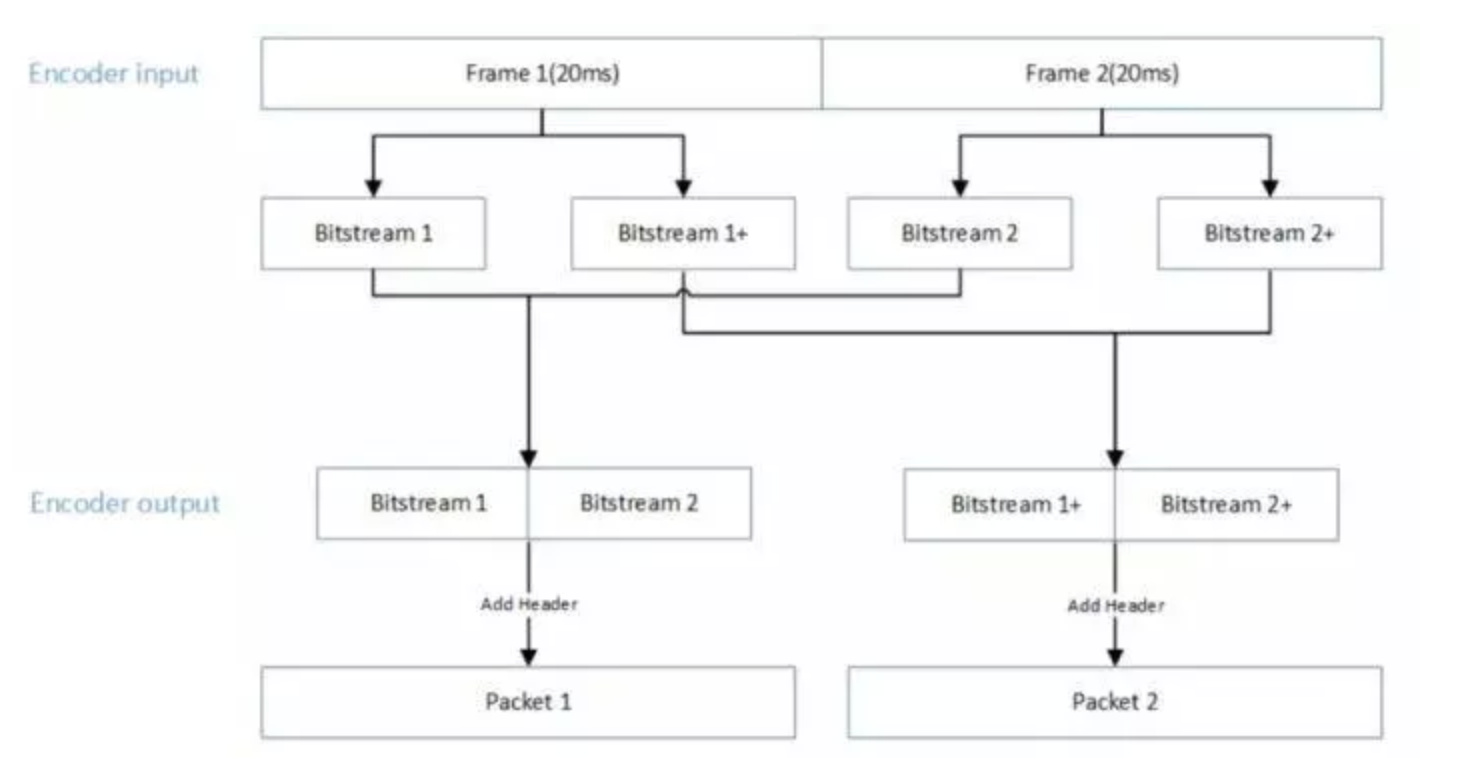
图 4. 编码器码流整合及组包
SOLO 默认配置为每次输入 40ms(2 帧),输出两段互补的多描述码流,解码器接收到任一段码流,即可解码出 40ms 的信号。为了方便接收端区分码流的顺序,码流第一个字节的右数第 4 个 bit 是码流顺序标志位,第一段码流标志位的值是 0,第二段码流标志位的值是 1。接收端在进行码流处理时,可依据此标志位进行码流顺序判断。
SOLO 已在 Github 开源,请点击这里跳转 Github。 如遇到疑问 ,请直接在 Github 提交 issue。









如何将 SOLO 集成 iOS 项目中去
集成到webrtc中,怎么判断互补包是否丢失?
测试好像不支持8000 采样率.如何设置才能使用8000采样率?
您好,我在github中下载代码后,编译arm里的代码test,测试发现solo编解码出来有杂音。用silk编解后并不会。