来自Pixabay的语音信号
本文介绍了语音信号及其分析。此外,我还与文本分析进行了比较,方便了解它与语音的不同之处。
作为交流媒介的语音和文本之比较
语音被定义为通过声音来表达思想和感受。语音是人类最自然、最直观、最喜欢的交流方式。语音的感知变异性以各种语言、方言、口音的形式存在,而语音的词汇量也在日益增加。语音信号级别有着更复杂的可变性,并以变化的幅度、持续时间、音调、音色和说话者可变性的形式存在。
文本作为一种通信手段,已演变为远距离存储和传递信息。它是任何语音交流的书面表示,是一种更简单的交流形式,且没有前面提到的语音中存在的复杂可变性。
语音中错综复杂的变化使得分析变得更加复杂,但使用音调和幅度变化可以提供额外的信息。
语音和文本的表示
语音和文本分析在当今世界有着广泛的应用。他们有不同的表示,在他们的分析中遇到了许多不同之处和挑战。
让我们看一下从CMU US RMS ARCTIC 语音数据库的一个话语中提取的语音信号。每段录音都被记录为采样频率为 16 kHz 的 16 位信号,这意味着信号的每秒有 16000 个样本,每个样本的分辨率为每个样本 16 位。音频信号的采样频率决定了音频样本的分辨率,采样率越高,信号的分辨率越高。从语音数据库中的 ‘arctic_a0005.wav’ 文件中读取语音信号,该文件的持续时间约为1.4秒,相当于22640个样本的序列,每个样本为16位数字。下面的语音表示是来自 “arctic_a0005.wav” 的语音信号图,其等效文本为 “我们会忘记它吗” :
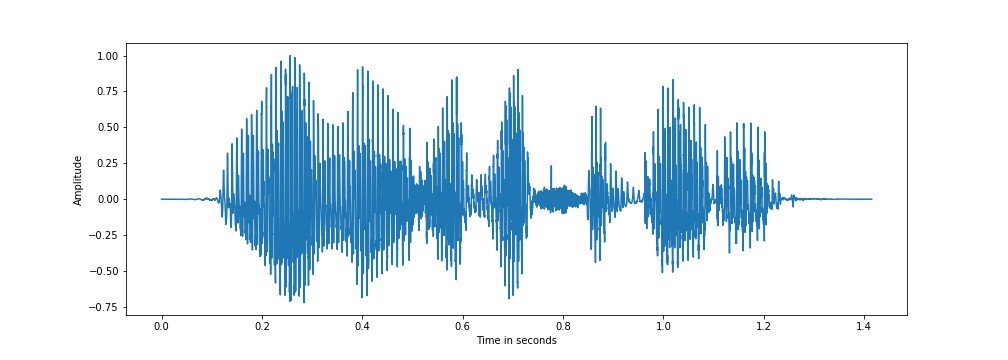
语音信号,s[n] 表示“我们会忘记它吗”
从上图可以看出,语音可以表示为幅度随时间的变化。幅度被归一类,使得最大值为 1 。语音基本上是一系列清晰的声音单位,如“w”、“ih”,称为音素。语音信号可以被分割成一系列音素和静音/非语音段。
该数据库还包含每个波形文件在句子和音素级别的语音信号的相应文本转录。下面是上述语音信号的部分表示,显示了音素及其相应的时间跨度。

‘will’ 信号的音素级段为 ‘w’、‘ih’ 和 ‘l’
从上图中可以看出,音素“w”、“ih”和“l”本质上是准周期性的,它们是由声带的周期性振动产生的,因此被归类为浊音。此外,“ih”是元音,而“w”和“l”是半元音。浊音和清音类是基于声带振动的语音的广泛分类。对不同音素的研究和分类称为语音学。
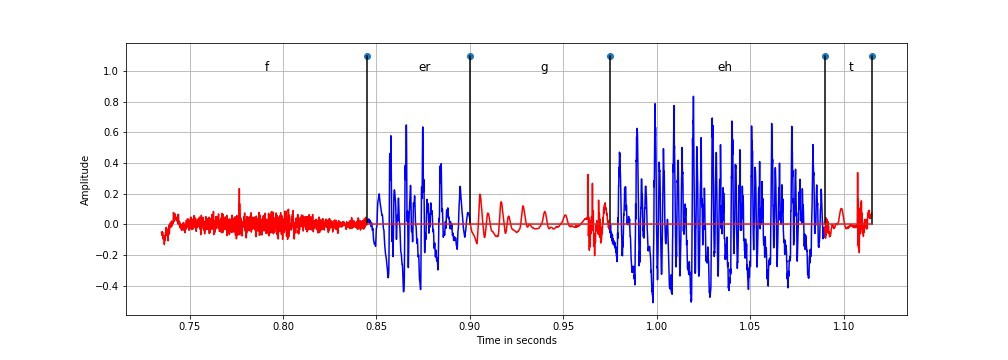
‘forget’ 信号的音素级段为 'f, ‘er’, ‘g’, ‘eh’ 和 ‘t’
在上图中,我们有像“f”、“g”和“t”这样的清音音素和像“er”和“eh”这样的浊音音素。音素 ‘g’ 和 ‘t’ 进一步归类为停顿,即突然出现的冲动之后的寂静。可以观察到,浊音分量是准周期性的,而清音分量是有噪声的,因为它们不是由声带的周期性振动产生的。
可以使用音素到字素映射将音素映射到语音的文本形式。下面是文本和相应音素之间的映射:
文字: “我们会不会忘记它”
音序:’ w’, ‘ih’, ‘l’, ‘w’, ‘iy’, ‘eh’, ‘v’, ‘er’, ‘f’, ‘er’, ‘g’, ‘eh’ , ‘t’, ‘ih’, ‘t’
从上面的映射可以看出,“will”这个词被映射到了音素 ’ w’、‘ih’、‘l’。
我们将进一步用研究语音的帧级频域表示,在语音研究界也称为 短时傅立叶变换 (STFT) 。 频谱图 是声音频域表示的直观表示。
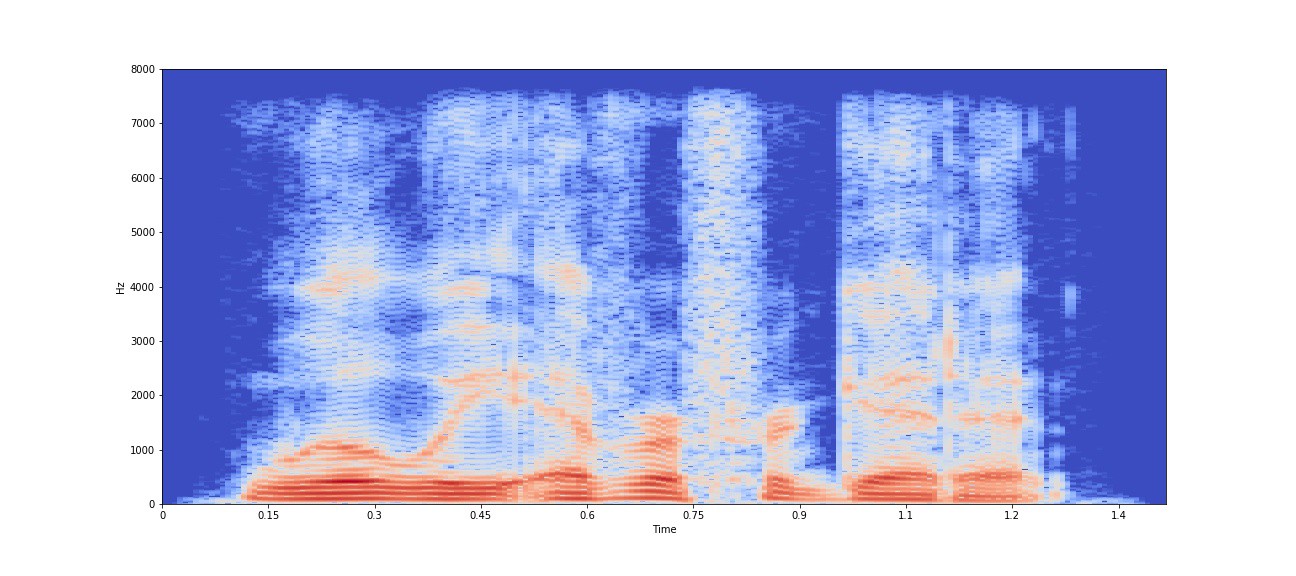
使用 30 ms 窗口大小和 7.5 ms 跳跃大小的语音信号的对数缩放频谱图
上面绘制的对数标度频谱图是对数标度中 STFT 的幅度。选择 30 ms 的帧大小,相当于 30 ms x 16 kHz = 480 个语音信号样本,而 7.5 ms 的帧偏移相当于 120 个样本。将语音信号分成小持续时间的帧的原因是语音信号是非平稳的,其时间特性变化非常快。因此,通过采用小帧大小,我们假设语音信号将是静止的,并且其特征在帧内变化不明显。此外,选择较短的帧移位来跟踪语音信号的连续性,并且不会错过帧边缘的任何突然变化。从上图中可以看出,每一帧的频域表示有助于我们更好地分析语音信号;因为我们可以很容易地将谐波视为浊区中的平行红色段,以及每个频率和帧索引的幅度如何变化。因此,语音信号的大部分分析是在频域中完成的。但是,由于将语音信号分成帧会丢弃信号中的瞬时变化,因此在时域中可以更好地捕获诸如信号中的突然变化(像“t”这样的突发的开始)等时间信息的提取。
我们可以说,通过采用更小的帧尺寸,我们可以在频域中获得更好的时间分辨率。但在时域和频域分辨率之间需要权衡。采用非常小的帧尺寸会提供更高的分辨率,但会在单个帧中提供较少的样本,并且相应的傅立叶分量的频率分量也会很少。由于样本数量较多,采用较大的帧尺寸会提供较低的时间分辨率和较高的频率分辨率。因此,不可能同时获得时间和频率的高分辨率。
可以看出,对于 16 kHz 的采样频率,对数频谱图中的 y 轴频率高达 8 kHz。这是因为,根据 Nyquist-Shannon 采样定理,在离散信号中可以观察到的最大频率最多是采样频率 8 kHz 的一半。
虽然根据环境、说话者、说话者的情绪和语气,语音有很多可变性,但文本不包含所有这些可变性。
等效文本表示为一系列字母、符号和空格,如“我们会忘记它吗”。
语音分析的应用
语音活动检测: 识别音频波形中仅存在语音的片段,忽略非语音和无声片段
语音增强: 通过从语音片段中过滤和分离噪声来提高语音信号的质量
语音识别: 将语音信号转换为文本,在不同条件下仍然是一个挑战,识别可以依赖于词汇或者不依赖词汇也可以
文本到语音: 从文本中合成自然语音,使带有情感的语音听起来非常自然变得具有挑战性
说话人二值化和说话人识别: 二值化是将语音信号分割成属于不同说话人的片段,而说话人识别是识别在特定时间说话的人
音频源分离: 分离混合语音信号,例如与来自不同说话者的语音或噪声重叠的语音
语音修改: 修改语音,如改变其情绪、语气,转换为不同说话者的语音
情绪语音分类: 识别 语音的 情绪,如高兴、愤怒、悲伤和焦虑
关键词 识别 : 识别整个语音中的特定关键词
文本分析的应用:
文本分类: 将整个文本文档分为不同的类,或将单词序列分为不同的类
命名实体识别: 识别人、组织、地名、某些缩写和其他实体
文本 摘要:从文档生成摘要
文档聚类: 根据相似的内容识别相似的文本文档
情感分析: 从文本中识别情绪、情绪、情绪和观点
语音和噪声分析的挑战:
语音和噪声分析的所有上述应用都非常具有挑战性。使语音和噪声分析进一步复杂化的外部因素是伴随语音和文本产生的各种噪声。探索各种信号处理、基于神经科学的方法、有监督和无监督的机器学习技术来解决相同的问题。由于语音信号的非结构化特性,基于深度学习的方法已在各种应用中取得成功。
语音和文本中的噪音:
噪声是任何使原始信号失真的无用信号。向语音添加噪声与向文本添加噪声是非常不同的。
给定幅度为 s[n] 的语音信号,其中 n 是样本索引,噪声是任何其他信号, w[n] 会干扰语音。带噪语音信号 u[n] 可以看作:
u[n]=s[n] + w[n]
在上述情况下,噪声本质上是可加的,这是最简单的情况。噪声也可能以卷积形式产生,例如混响、幅度削波和语音信号的其他非线性失真。
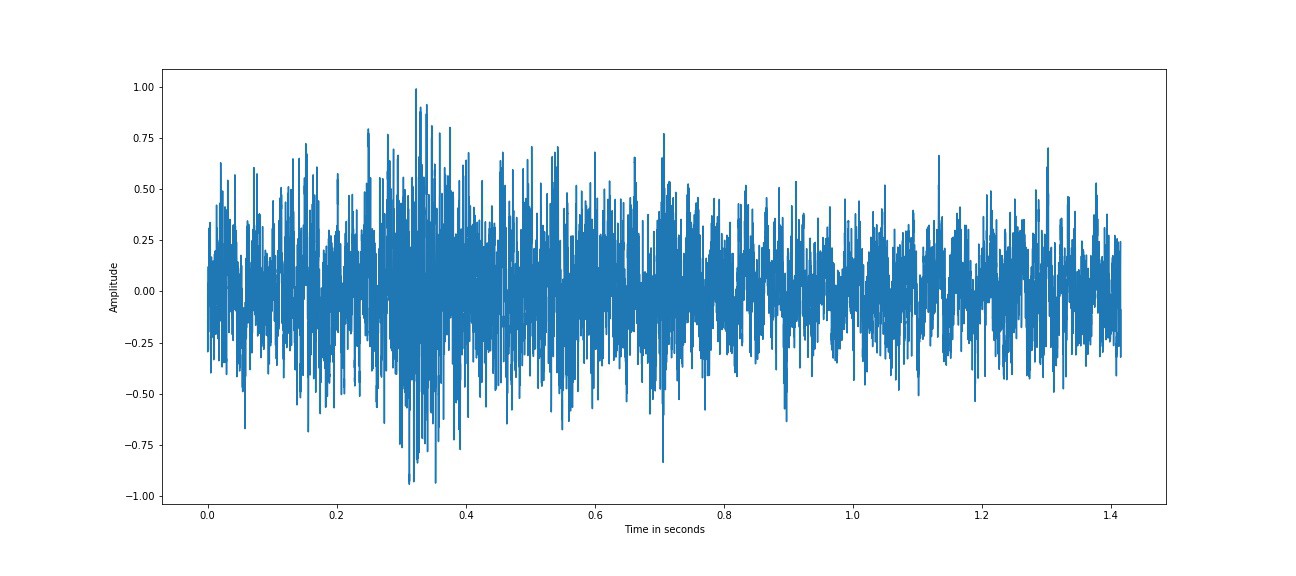
factory1 噪声,来自 NOISEX92 数据库的 w[n]
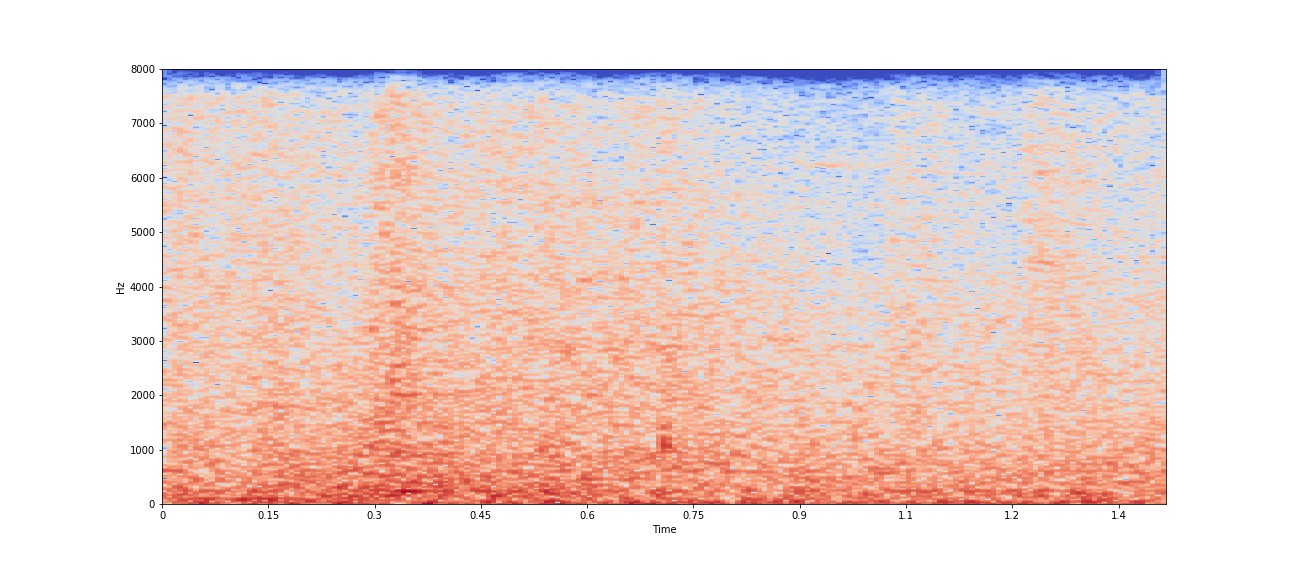
使用 30 ms 窗口大小和 7.5 ms 跳跃大小的 factory1 噪声的对数缩放频谱图
上图是从NOISEX92数据库中获取的factory1 时域和频域噪声。上述噪声样本被重新采样为相同的语音样本采样率,16 kHz,因为我们将语音添加到噪声中,并且两者都应该具有相同的采样率。
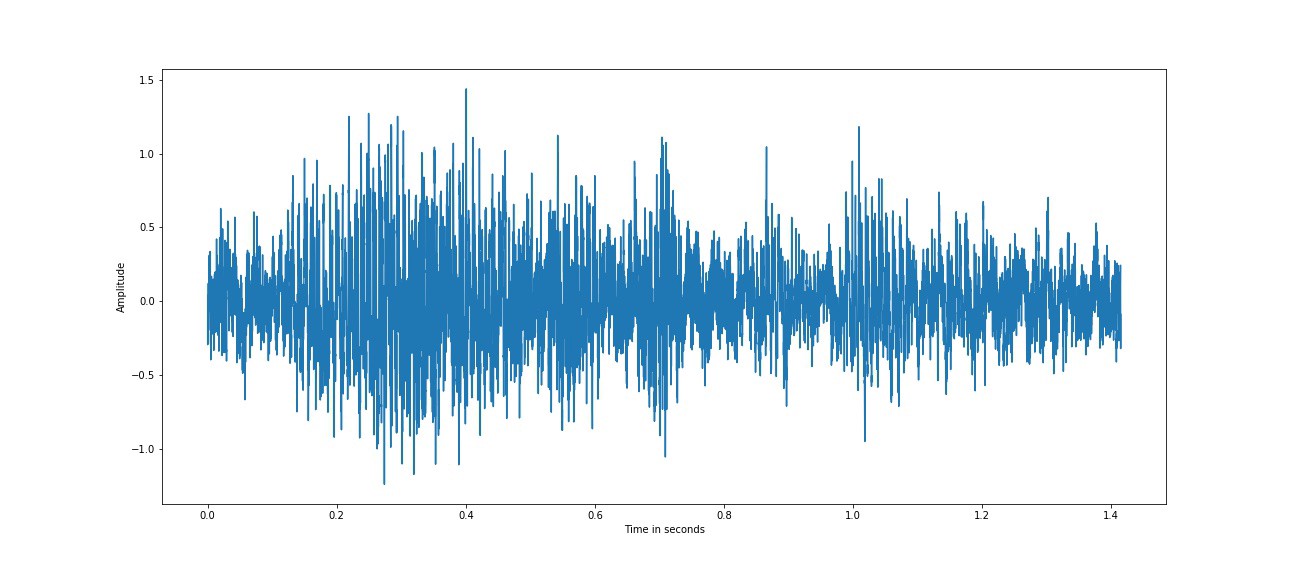
噪声语音,u[n] 在 0dB 的 SNR
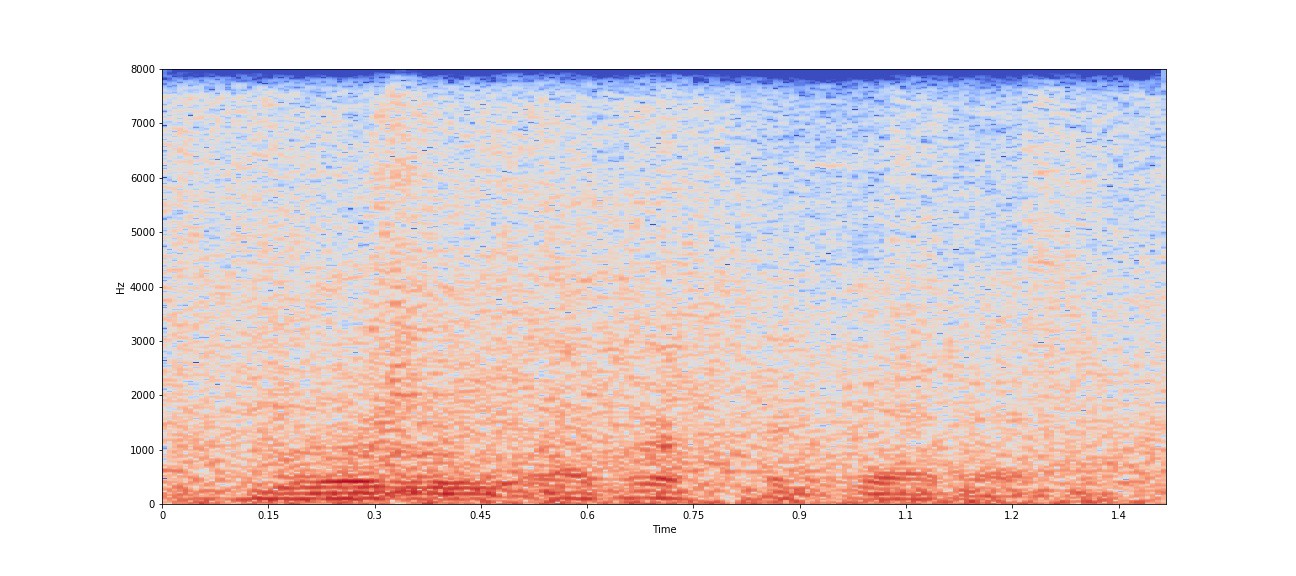
使用 30 ms 的窗口大小和 7.5 ms 的跳跃大小对噪声语音进行对数缩放的频谱图
上图是时域和频域中的嘈杂语音。语音信号中的噪声会修改整个信号,并且很难分析和提取语音片段。各种语音增强算法的存在可减少噪声分量并提高语音的可懂度。
在给定的文本句子,噪音可能会以拼写错误和遗漏单词的形式产生,这可能会改变句子的含义或创建无意义的句子。例如:
原文句子: ‘我们会忘记它吗’
嘈杂的文字句子: ‘我们永远不会忘记它’
在上述嘈杂的文本中,噪声以单词“ ever” 变为 “never”的形式产生, 从而改变了句子的含义。
另一种形式的嘈杂文本: “我们永远不会忘记它”
在上述嘈杂的文本中,噪声以“ 忘记” 一词更改为 “forggt”的 形式产生,由于拼错单词 “forggt” 而使句子变得毫无意义。
因此,可以看出,在语音中添加噪声会使整个信号失真,而在文本中,失真是离散的,如丢失字符/单词或拼写错误。
语音分析的插图
我们现在将说明一种重要的语音分析技术。任何音频信号的录音通常都包含许多静音区域,我们可能只对存在语音的片段感兴趣。这对于从包含长静音区域的信号中自动提取语音段很有用,因为静音区域不传达任何信息。这些语音片段可以进一步分析用于各种应用,如语音识别、说话者和情感分类。
因此,静音检测是大多数语音应用中重要的预处理步骤。
给定一个语音信号 s[n] ,可以通过比较短时间段内的相对能量来检测静音区域。我们取20ms的帧大小,并计算短期能量信号, E [N] 为平方和 S [米] ,其中 米 距离的+/- 10毫秒(在样品) ñ 。 帧大小的选择取决于我们想要检测的语音信号的能量随时间的多少变化。短帧大小能够检测到能量的突然变化,但由于某些音素(如突发和单词之间)中固有的静音部分,可能会产生许多静音段的交替帧。
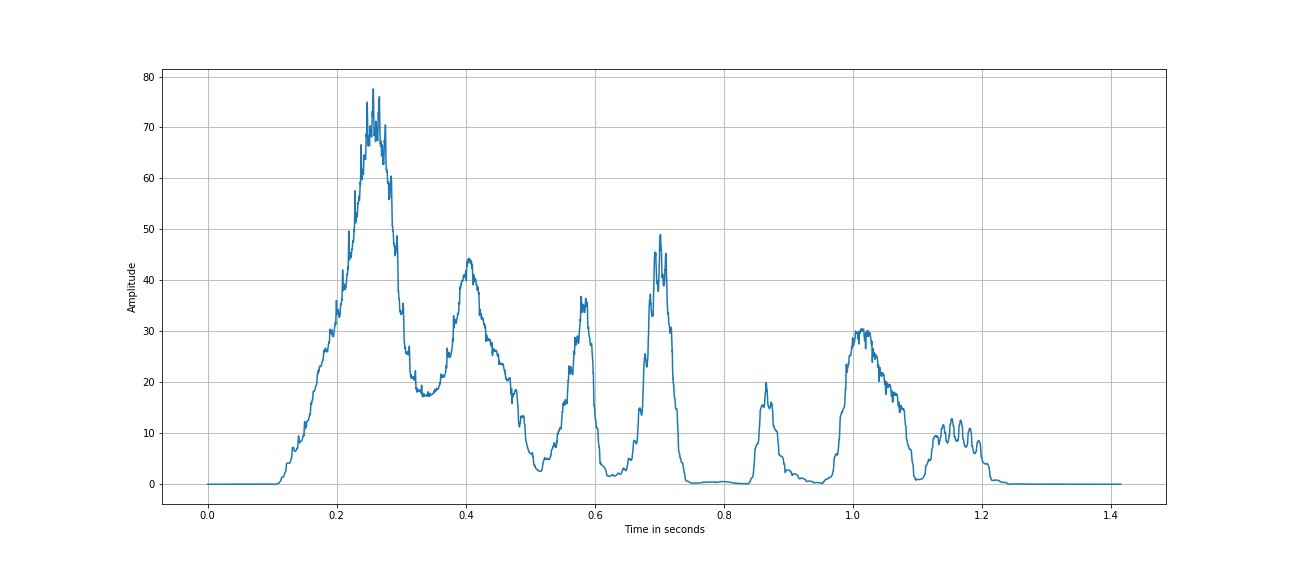
语音信号的短期能量,e[n]
从上图中可以看出,语音信号的短期能量变化很大,可以使用相对阈值来检测静音区域。

语音信号中的静音检测
上图显示了使用语音信号平均短期能量的 0.01% 的阈值以红色突出显示的静音区域。基于对语音信号中短期能量变化的观察来选择阈值。
静音检测的一个挑战是,如果语音信号有噪声,那么语音静音区域的相对能量也会很高。这可以通过查看低通滤波语音信号的短期能量变化来解决,以防噪声主要具有高频分量。
这可以在 G it h u b 和 NBV ie w er 找到本文中完成的模拟演示。
希望本文的内容和演示能对你有所帮助。在接下来的文章中,我将尝试添加更多关于语音信号分析的见解。
原文作者 K V Vijay Girish
原文链接 https://towardsdatascience.com/beginners-guide-to-speech-analysis-4690ca7a7c05