


声网Agora Native SDK 3.4.0 本月已正式上线。新版本不仅增加了更丰富的实时美声音效、屏幕共享、虚拟节拍器等功能,同时在 SDK 的稳定性、兼容性及安全合规上做了大幅度升级,希望为 App 用户带来更顺畅、舒适的互动新体验。
3.4.0 版本更新了什么?
功能新增
1、音效文件播放进度
在实时音视频互动过程中,当我们希望可以更好地烘托气氛、增添趣味性,通常会选择播放音效(例如,在游戏中添加打斗声,在唱歌时添加伴奏等)来进行互动。但有时候如果需在播放音效文件后调整播放位置,只单独播放一个完整音轨中的某一段或者希望快速跳过某部分音频内容,3.4.0 版本中提供了控制音效文件的播放进度。具体新增如下方法:
-
playEffect3:通过startPos参数,在播放音效文件时设置播放位置。 -
setEffectPosition: 在播放音效文件后,设置音效文件的播放位置。 -
getEffectDuration: 获取本地音效文件的总时长。 -
getEffectCurrentPosition: 获取音效文件的播放进度。
2、虚拟节拍器
为满足在线音乐教学等场景对节拍器的需求,3.4.0 版本新增如下方法:
-
startRhythmPlayer: 开启虚拟节拍器。 -
stopRhythmPlayer: 关闭虚拟节拍器。 -
configRhythmPlayer: 在开启虚拟节拍器后,重新配置虚拟节拍器。
功能优化
1、弱网下的视频流畅性与质量平衡
在带宽受限时,为了保证视频的流畅性,通常视频编码会选择优先降低视频帧率维持视频质量不变或者选择降低视频质量保障视频帧率。但在一对一通话、一对一教学或多人会议的场景中,画质与流畅性其实都很难割舍。因此,在 3.4.0 版本中我们对此对了优化degradationPreference新增支持设为 AgoraDegradationBalanced,弱网下会降低视频帧率和视频质量,以在流畅性和视频质量之间取得平衡。
2、原始视频数据(C++)
为方便开发者获取传输各阶段的视频原始数据,满足更多场景需求,在 3.4.0 之前的版本中我们已经支持 C++ 回调 getRotationApplied 和 getMirrorApplied将原始视频数据作旋转、镜像处理。为提升用户体验,新版本将这些回调函数支持处理的视频数据格式由 RGBA 拓展到 RGBA 和 YUV 420。
3、屏幕共享功能优化
实时互动场景中的屏幕共享是指将屏幕上的内容分享,从而实现信息共享的一种技术。这样的应用在游戏直播、视频会议或在线教育场景中都较为常见(文件、数据、网页、课件、笔记等屏幕共享),用户可以将自己移动端或 PC 端的屏幕内容共享给他人实时观看。
新版本的 SDK 目前已支持屏幕区域共享、窗口区域共享、全屏共享、共享前置、窗口最小化回调等功能,同时还支持流畅性有先模式或清晰度优先模式的选择。在屏幕共享的可用性及体验感上都做了很大都提升。
4、客户端录音
为了便于用户在录音时可以更方便、灵活地设置录音内容,该版本新增startAudioRecordingWithConfig方法,通过startAudioRecordingWithConfig的config参数,用户可自主选择设置录音音质、内容、采样率及录音文件的存储路径。
同时,该版本还新增了错误码 AgoraErrorCodeAlreadyInRecording(160)。如果在音乐文件播放完成前再次调用 startAudioRecordingWithConfig,SDK 会报告该错误码。
为什么是目前最“优”版本?
Agora Native SDK 3.4.0 是一个功能更丰富、稳定性更高的集大成版本。为了用户在新版本中拥有更好的体验。我们从 3.0 SDK 到 3.4 SDK 的过程中做了诸多的优化,在音频处理、视频处理、延时优化、安全合规等方面都做了相应的提升。因此,3.4 版本不仅新增和优化了部分功能,同时也保留和优化了之前版本中优秀的功能与特性。
1、3A算法+AI 高效降噪
不管是在视频面试还是视频会议场景中,我们都曾遭遇过因为噪音、回声等,暂时中止双方的互动,或者重新加入视频房间的情况。
通过声网的 3A (AEC、ANC、AGC)算法,可实现智能适应各类环境,全面消除回声,并提供超一流的双讲表现;可在不损伤语音音质的情况下,有效消除各类噪音;可实现音频的自动增益,即使在嘈杂环境下用户也能有很好的实时互动体验。
同时,声网 SDK 在降噪模块的前端预置了信号分类模块,能够精确地检测出信号的类型,并根据信号的类型调整降噪算法的类型及参数,常见的信号类型包括一般语音、清唱、音乐信号等。通过声网的 AI 降噪算法,利用深度学习技术通过特征提取、神经网络以及增益调整对实时音频进行处理抑制噪声,突破了传统信号处理方案的性能瓶颈,从而为实时音视频提供清晰语音环境。可实现良好降噪效果,解决了实现实时人声和噪声分离的同时保证人声保真度的降噪难题。
想要详细了解此部分内容的小伙伴可参考「详解低延时高音质:回声消除与降噪篇」
2、更丰富的美声音效
实时音效是指为声音增加某种特定的风格,增强声音的层次感和空间感。为提高用户的音频体验,我们将传统专业声卡、调音师、万元级线下插件通过软件算法的方式搬到线上,用户无需再专门下载插件就可以使用美声特效、虚拟立体声、美化音色、自动变声等声音特效,在提升用户体验和场景娱乐性的同时极大的降低了使用门槛。
目前已实现 3种语聊美声、6种歌唱美声、8种音色变换、18种人声音效、7种变声音效、4种基础变声效果。
Demo试听:https://www.agora.io/cn/audio-demo想了解实时美声的原理,可阅读我们往期的分享。接口具体使用方法,可以访问声网文档中心,搜索并查看高阶指南「变声与混响」。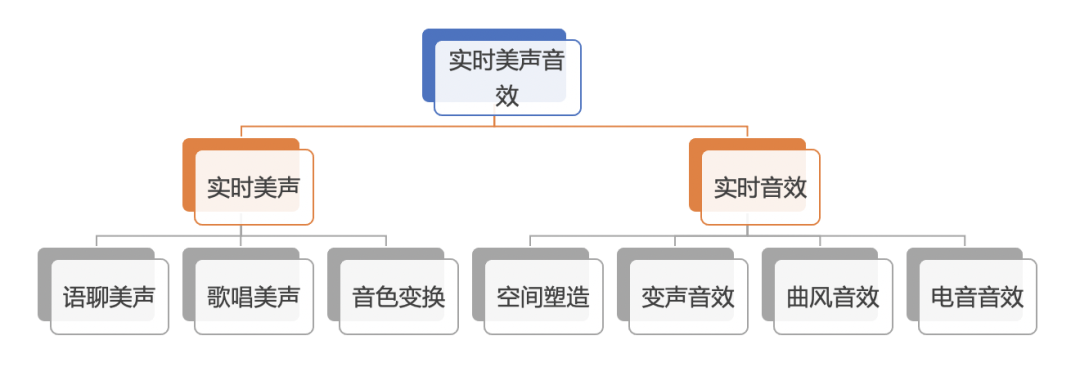
3、美颜优化-兼具“自然”与“美”
在社交娱乐或教育场景中,用户进行视频通话或直播时,常常希望向对方呈现良好的状态和精神面貌。通过聚焦人像皮肤、头发和背景等区域,帮助开发者轻松实现更真实、更“自然”的美白和红润效果,开发者们还可以通过调整参数来自定义美颜效果。

即便在极端暗光条件下,通过应用声网自研暗光增强算法,可自适应调整光照过暗区域的亮度值,恢复和凸显图像的细节信息,提升视频图像的视觉效果,让视频画面拥有更自然的优质画质。此功能适用于整体亮度偏低、背光、阴天、光照不均匀等场景。暗光增强目前支持 iOS 平台,在使用效果和设备性能间做好平衡调优,可在 iPhone 6s 机型及以上支持 720P@30fps 的实时处理。
4、80%抗丢包能力,SDK 崩溃率「万分之一」
在实时数据传输质量的优化上,基于声网 SD-RTN™ 的传输,在包到达率上,SD-RTN™ 与专线已无差别,jitter 200ms 的到达率为 99.9%。稳定性已达到专线水平。
同时,针对实时语音互动中可能出现的弱网传输、丢包等情况,声网Agora 拥有一套专业的抗弱网传输与抗丢包算法。在 SDK 迭代的过程中,我们也不断地对其背后的抗弱网指标进行着优化,目前视频的抗弱网边界已经从原来的 60% 提升至 70%,音频则已经提升至 80%,在这样的弱网环境下,仍可以保证音频、视频的流畅体验。同时,根据美洲,亚洲,东南亚,中东等地区用户提供的数据显示,SDK 首帧出图、出声时间也得到了全面的优化,客户闭环验证结果与实验室测试结果完全吻合。
5、安全合规
声网遵循国际认可的信息安全和隐私保护标准以及行业要求,致力于采用国际最佳实践来建设隐私和安全管理体系。目前声网已经通过 ISO/IEC 27001、ISO/IEC ISO27017、ISO/IEC 27018 体系认证,并获得了由第三方专业机构出具的SOC2 Type I服务鉴证报告,以此证明自身的隐私合规和安全管理能力。

关于此次新版本的更多特性与新增功能可能无法在此次的介绍中一一赘述,点击【此处】在线获取更多 SDK 相关资讯。








